고정 헤더 영역
상세 컨텐츠
본문

Writer: Harim Kang
머신러닝 - 3. End-to-End Machine Learning Project (2)
해당 포스팅은 머신러닝의 교과서라고 불리는 Hands-On Machine Learning with Scikit-Learn & Tensor flow 책을 학습하며 정리하고, 제 생각 또한 함께 포스팅한 내용입니다. 아래의 포스팅에 이어진 내용입니다.
https://learning.oreilly.com/library/view/hands-on-machine-learning/9781491962282/ch02.html의 내용과 제 조사 및 생각을 함께 정리한 포스팅입니다.
2020/01/21 - [IT/Machine Learning] - 머신러닝 (2) - ML프로젝트를 위한 데이터 선택 및 준비 (using Scikit-Learn)
머신러닝 (2) - ML프로젝트를 위한 데이터 선택 및 준비 (using Scikit-Learn)
Writer: Harim Kang 머신러닝 - 2. End-to-End Machine Learning Project (1) 해당 포스팅은 머신러닝의 교과서라고 불리는 Hands-On Machine Learning with Scikit-Learn & Tensor flow 책을 학습하며 정리하고,..
davinci-ai.tistory.com
오늘의 포스팅은 위의 포스팅에 이어지는 데이터 전처리 과정에 대한 포스팅입니다. 해당 포스팅은 Data Cleaning, text or categorical feature encoding, Data Transformation, Data Scaling, Pipeline에 대한 내용을 포함하고 있으며, Scikit-learn 라이브러리 메서드를 사용한 전처리에 대해 포스팅하였습니다.

데이터 전처리
데이터 전처리는 기존의 데이터를 머신러닝 알고리즘에 알맞은 데이터로 바꾸는 과정입니다. 이 전처리 과정은 모델이 생선 된 이후에도 예측하고자 하는 새로운 데이터에도 적용하는 과정입니다. 또한, 전처리 과정을 통해서 더욱더 모델 학습의 성능을 높일 수 있습니다.
데이터 전처리 과정
- Data Cleaning
- Handling Text and Categorical Attributes
- Custom Transformers
- Feature Scaling
- Transformation Pipelines
Data Cleaning
대부분의 머신러닝 알고리즘은 Missing feature, 즉 누락된 데이터가 있을 때, 제대로 역할을 하지 못합니다. 그래서 첫번째 방법으로 먼저 Missing feature에 대해 처리해주어야 합니다.
-
불 필요 데이터 제거(처리)
- dropna() : pandas에서 제공하는 누락 데이터를 제거하는 함수입니다.
- Na/NaN과 같은 누락 데이터를 제거하는 함수입니다.
- axis: 파라미터 값으로 0을 주면 행 제거, 1을 주면 열 제거입니다. default값은 0입니다.
- subset: array, 특정 feature를 지정하여 해당 Feature의 누락 데이터 제거가 가능합니다.
- dropna() : pandas에서 제공하는 누락 데이터를 제거하는 함수입니다.
-
전체 속성 제거 : 연관성 없는 feature의 경우, 학습에 방해가 될 수 있기 때문에 제거합니다.
- drop() : pandas에서 제공하는 특정 데이터 열(또는 행)을 제거하는 함수입니다.
- 특정 행 또는 열의 라벨(데이터)들을 제거합니다.
- labels: 제거할 데이터를 지정하는 파라미터입니다.
- axis: 파라미터 값으로 0을 주면 행 제거, 1을 주면 열 제거입니다. default값은 0입니다.
- drop() : pandas에서 제공하는 특정 데이터 열(또는 행)을 제거하는 함수입니다.
-
누락 데이터에 특정 값을 지정 : zero(0으로 채우기), the mean(평균값으로 채우기), the median(중간값으로 채우기) 등등의 값을 누락 데이터에 채우는 방식입니다.
- fillna() : pandas에서 제공하는 누락 데이터에 특정 값을 채우는 함수입니다.
- 특정 메서드를 지정하여 Na/NaN값을 채웁니다.
- value: scalar, dict, series or dataframe, value 등 구멍을 메우기 위한 값
- fillna() : pandas에서 제공하는 누락 데이터에 특정 값을 채우는 함수입니다.
-
scikit-learn에서 제공하는 클래스
-
Imputer() class
-
missing_values: int or 'NaN'
-
strategy: 'median'(중앙값), 'mean'(평균값), 'most_frequent'(최빈값)
-
axis: 0(columns), 1(rows)
-
사용법
-
Imputer Class를 선언합니다. 채우고자 하는 값을 함께 정의합니다.
from sklearn.preprocessing import Imputer imputer = Imputer(strategy='median') -
fit() 함수를 사용하여 기존 데이터의 누락 데이터에 채워야 할 값을 imputer 객체에 훈련시킵니다.
imputer.fit(dataset) -
transform() 함수를 사용하여 기존 데이터의 누락 데이터를 변환합니다.
X = imputer.transform(dataset)
-
-
-
문자와 카테고리형 데이터 다루기
대부분의 ML알고리즘들은 숫자 데이터로 학습하는 것을 선호합니다. 기존 데이터 세트에 텍스트가 있는 경우 이것을 숫자형 데이터로 인코딩해주어야 합니다. 방법은 아래와 같습니다.
-
Encoding
- Encoding text to number method : factorize(), OrdinalEncoder()
- One-Hot Encoding method : OneHotEncoder()
-
예제로 사용할 데이터
>>> housing_cat = housing[["ocean_proximity"]] >>> housing_cat.head(10) ocean_proximity 17606 <1H OCEAN 18632 <1H OCEAN 14650 NEAR OCEAN 3230 INLAND 3555 <1H OCEAN 19480 INLAND 8879 <1H OCEAN 13685 INLAND 4937 <1H OCEAN 4861 <1H OCEAN >>> housing_categories Index(['<1H OCEAN', 'INLAND', 'ISLAND', 'NEAR BAY', 'NEAR OCEAN'], dtype='object') -
factorize()
-
Pandas에서 제공하는 메서드로서, 숫자형 또는 카테고리형으로 인코딩을 해주는 함수입니다.
-
여러 개의 카테고리형 input feature들을 인코딩할 수 있습니다.
-
파라미터
- values: a 1-D array, factorization전의 배열
- sort: bool, default False, 관계를 유지하면서 unipue 한 카테고리 label을 준비합니다.
-
Returns
-
labels: ndarray, 인코딩 된 결과를 배열로 리턴합니다.
-
uniques: ndarray, 카테고리를 배열로 리턴합니다.
housing_cat_encoded, housing_categories = housing_cat.factorize() [0 0 1 2 0 2 0 2 0 0 2 2 0 2 2 0 3 2 2 2 0]
-
-
-
OrdinalEncoder()
-
Scikit-learn에서 제공하는 factorize 역할의 클래스라고 생각하면 될 거 같습니다.
-
OrdinalEncoder객체를 생성해서, inputer와 비슷한 방식으로 사용합니다. 대신, fit_transform() 메서드를 사용하여, fit과 transform을 한 번에 제공합니다.
from sklearn.preprocessing import OrdinalEncoder ordinal_encoder = OrdinalEncoder() housing_cat_encoded = ordinal_encoder.fit_transform(housing_cat)** > housing_cat_encoded[:10] > array([[0.], > > > [0.], > [4.], > [1.], > [0.], > [1.], > [0.], > [1.], > [0.], > [0.]]) >
-
-
위의 factorize()와 OrdinalEncoder()와 같은 카테고리형 텍스트를 단순히 순서에 맞게 숫자형으로 바꾸어주는 방법은 문제점이 있습니다. 예를 들어 위의 함수들을 사용해서 변환시키면 <1H OCEAN변수는 0이고, NEAR OCEAN변수는 4입니다. 각각 변수들은 0~4까지 있는데, 1 같은 경우 0과 비슷하다고 ML알고리즘은 판단할 수 있습니다. 실제로는 비슷하지 않지만, 알고리즘은 숫자에 의미를 두어 거리를 판단하게 되는 경우가 생깁니다. 이를 방지하기 위해서 나온 것인 One-Hot Encoder입니다.
-
OneHotEncoding()
-
Scikit-learn에서 제공하는 클래스로, 카테고리형 특징들을 one-hot 숫자형 배열로 인코딩해주는 클래스입니다.
-
오직 하나로 해당되는 부분만 1(Hot)로, 나머지는 0(Cold)으로 바꾸는 방법입니다.
from sklearn.preprocessing import OneHotEncoder cat_encoder = OneHotEncoder() > housing_cat_1hot = cat_encoder.fit_transform(housing_cat) > housing_cat_1hot > <16512x5 sparse matrix of type '<class 'numpy.float64'>' > with 16512 stored elements in Compressed Sparse Row format> -
위와 같은 코드로 사용합니다. OrdinalEncoder와 비슷한 방식으로 사용됩니다. 아래에는 numpy배열로 변환한 코드입니다.
>>> housing_cat_1hot.toarray() array([[1., 0., 0., 0., 0.], [1., 0., 0., 0., 0.], [0., 0., 0., 0., 1.], ..., [0., 1., 0., 0., 0.], [1., 0., 0., 0., 0.], [0., 0., 0., 1., 0.]])
-
Custom Transformers
Scikit-learn에서는 다양한 데이터 변환기(Transformer)들을 제공합니다. 이를 이용하여, 커스텀 변환기를 만들 수 있습니다. 이를 위해서는 세 가지 메서드를 알아야 합니다.
-
fit()
- x: input data
- x라는 데이터에 특정 알고리즘 또는 전처리를 적용하는 메서드입니다. 이를 통해 변환기에 알맞는 파라미터를 생성합니다.
-
transform()
- x: input data
- fit()을 통해 생성된 파라미터를 통해서 모델을 적용시켜 데이터 세트를 알맞게 변환시키는 메소드입니다.
-
fit_transform()
-
같은 데이터 세트를 사용하여 fit과 transform을 한 번에 하는 메서드입니다.
from sklearn.base import BaseEstimator, TransformerMixin rooms_ix, bedrooms_ix, population_ix, households_ix = 3, 4, 5, 6 class CombinedAttributesAdder(BaseEstimator, TransformerMixin): def __init__(self, add_bedrooms_per_room = True): # no *args or **kargs self.add_bedrooms_per_room = add_bedrooms_per_room def fit(self, X, y=None): return self # nothing else to do def transform(self, X, y=None): rooms_per_household = X[:, rooms_ix] / X[:, households_ix] population_per_household = X[:, population_ix] / X[:, households_ix] if self.add_bedrooms_per_room: bedrooms_per_room = X[:, bedrooms_ix] / X[:, rooms_ix] return np.c_[X, rooms_per_household, population_per_household, bedrooms_per_room] else: return np.c_[X, rooms_per_household, population_per_household] attr_adder = CombinedAttributesAdder(add_bedrooms_per_room=False) housing_extra_attribs = attr_adder.transform(housing.values)
-
-
위의 코드는 rooms_per_household, population_per_household 두 변수의 데이터를 생성하는 코드입니다.
위의 코드를 통해 이해한 내용으로는, fit함수 작성을 통해 데이터 세트를 받아서 객체를 return 하고, transform을 통해 데이터 세트를 실질적으로 변환(생성)시킨다는 것을 알 수 있습니다.
Feature Scaling
숫자형으로 다 바꾼 데이터를 바로 학습시킨다면 좋은 성능을 가진 모델이 될까요? 일반적인 ML 알고리즘들은 아주 다양한 범위의 숫자형 데이터를 학습시킨다면 제대로 성능을 보여주지 못합니다.
예를 들어, 특정 데이터의 범위가 -500~39,320이라면 아주 다양한 데이터가 존재합니다. 이러한 상태에서는 제대로 된 학습을 잘하지 못합니다. 이를 방지하기 위해서 숫자형 데이터의 범위를 줄여주는 방법을 사용합니다.
-
Min-Max Scaling (Normalization)
-
최솟값과 최댓값을 확인하여 이 값들을 모두 지정한 범위(대체로 0과 1 사이)의 상대적인 값으로 변환시키는 방법입니다.
-
특정 범위를 지정하면 해당 범위 안으로 바인딩시키는 방법입니다.
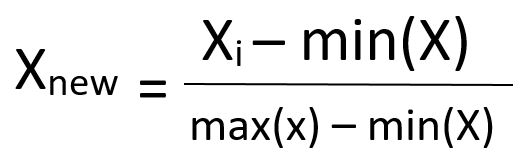
-
Scikit-learn에서는 MinMaxScaler(feature_range, copy) class를 제공합니다.
-
feature_range: tuple(min, max), default=(0, 1), 변환하고자 하는 데이터의 변환 지정 범위입니다.
-
copy: Boolean, 변환 이전의 값들을 복사해 둘 것인지에 대한 여부입니다.
from sklearn.preprocessing import MinMaxScaler a = [[10, 2, 1], [9, 2, 1], [8, 2, 1], [6, 2, 5], [2, 8, 10]] scaler = MinMaxScaler(feature_range=(0,1)) a = scaler.fit_transform(a) >>> print(a) [ [1. 0. 0.] [0.875 0. 0.] [0.75 0. 0.] [0.5 0. 0.44444444] [0. 1. 1.]]
-
-
-
Standardization
-
특정 범위에 값을 바인딩하지 않습니다.
-
특정 알고리즘(ex. Neural Network)에서는 사용되지 않는 방식입니다.
-
특이점(이상점)의 영향이 적습니다.
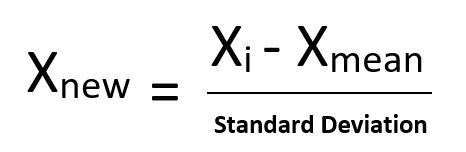
-
Scikit-learn에서는 StandardScaler() 클래스를 제공합니다.
from sklearn.preprocessing import StandardScaler a = [[10, 2, 1], [9, 2, 1], [8, 2, 1], [6, 2, 5], [2, 8, 10]] scaler = StandardScaler() a = scaler.fit_transform(a) >>> print(a) [ [1.06066017 -0.5 -0.73130714] [0.70710678 -0.5 -0.73130714] [0.35355339 -0.5 -0.73130714] [0.35355339 -0.5 0.39378077] [-1.76776695 2. 1.80014064]]
-
ML Pipeline
위의 데이터 전처리 방식들은 아주 다양한 컴포넌트들로 이루어져 있습니다. 매번 데이터 정제마다 같은 순서를 반복하기 싫다면, Pipeline이라는 방식을 사용하면 됩니다.
Pipeline은 Data Processing Component들의 순서를 정의해놓은 것입니다.
- 데이터 변환을 조작하고 적용하는 방법입니다.
- 각각의 컴포넌트들과 교류하며 사용합니다.
- ML 워크플로우의 자동화를 돕는 방법입니다.
Scikit-Learn에서는 Pipeline Class를 제공합니다. 이것은 데이터 변환 단계의 순서를 정리하고 만들기 쉽게 합니다.
-
Parameter
- steps: list, list of tuple
-
마지막에 사용되는 estimator는 반드시 데이터 변환 단계를 필요로 합니다. (fit_transform이 포함되어야 합니다.)
from sklearn.pipeline import Pipeline from sklearn.preprocessing import StandardScaler num_pipeline = Pipeline([ ('imputer', SimpleImputer(strategy="median")), ('attribs_adder', CombinedAttributesAdder()), ('std_scaler', StandardScaler()), ]) housing_num_tr = num_pipeline.fit_transform(housing_num)
위의 코드에서, Pipleline클래스에 imputer, 특성 추가, StandardScaler()를 모두 선언하여 데이터가 해당 순서에 맞춰 진행되도록 하는 코드입니다.
다음 포스팅에서는 이어서 ML 알고리즘, 모델 선정, 학습, 평가 등에 관한 내용을 작성할 예정입니다.
머신러닝 입문 관련 데이터 세트 프로젝트는 아래의 github 레포지토리에 있습니다.
https://github.com/harimkang/Scikit-Learn-Example
harimkang/Scikit-Learn-Example
Analyze and predict various data to learn how to use Scikit-learn - harimkang/Scikit-Learn-Example
github.com
Reference
https://learning.oreilly.com/library/view/hands-on-machine-learning/9781491962282/ch02.html#
https://www.geeksforgeeks.org/ml-feature-scaling-part-2/
반응형
'IT > Machine Learning' 카테고리의 다른 글
| 머신러닝 (5) - Cross Validation(교차검증) (9) | 2020.01.28 |
|---|---|
| 머신러닝 (4) - ML 모델 생성과 훈련, 예측, 평가 (2) | 2020.01.28 |
| 머신러닝 (2) - ML프로젝트를 위한 데이터 선택 및 준비 (0) | 2020.01.21 |
| 추천 시스템 (2) - 실제 시스템 분석 (3) | 2020.01.14 |
| 추천 시스템 (1) - 개요 및 알고리즘 (2) | 2020.01.08 |




