고정 헤더 영역
상세 컨텐츠
본문

Writer: Harim Kang
머신러닝 - 5. End-to-End Machine Learning Project (4)
해당 포스팅은 머신러닝의 교과서라고 불리는 Hands-On Machine Learning with Scikit-Learn & Tensor flow 책을 학습하며 정리하고, 제 생각 또한 함께 포스팅한 내용입니다. 아래의 포스팅에 이어진 내용입니다.

2020/01/28 - [IT/Machine Learning] - 머신러닝 (4) - ML 모델 생성과 훈련, 예측, 평가
머신러닝 (4) - ML 모델 생성과 훈련, 예측, 평가
Writer: Harim Kang 머신러닝 - 4. End-to-End Machine Learning Project (3) 해당 포스팅은 머신러닝의 교과서라고 불리는 Hands-On Machine Learning with Scikit-Learn & Tensor flow 책을 학습하며 정리하고,..
davinci-ai.tistory.com
오늘의 포스팅은 위의 포스팅에 이어지는 내용으로, 교차 검증 Cross-Validation에 대한 내용입니다. 해당 포스팅은 Cross-Validation, KFold, StratifiedKFold, cross_val_score(), cross_validate() 에 대한 내용을 포함하고 있으며, Scikit-learn 라이브러리 메서드를 사용하여 코드를 작성하였습니다.
Cross-Validation (k-Fold Cross Validation)
모델을 생성하고 예측했다고 해서 모델이 좋은 예측을 하는 것은 아닙니다. 훈련 시에는 좋은 점수를 얻었지만, 훈련에서 너무 안 좋은 점수를 얻는 경우가 생깁니다. 이를 과적합(Overfitting)이라고 합니다. 이것을 피하기 위해서 훈련 데이터 세트 전체를 한 번에 훈련시키지 않고, 일부를 남겨두고 테스트하는 것에 사용합니다. 이러한 방법을 Cross-Validation, 교차 검증이라고 합니다.
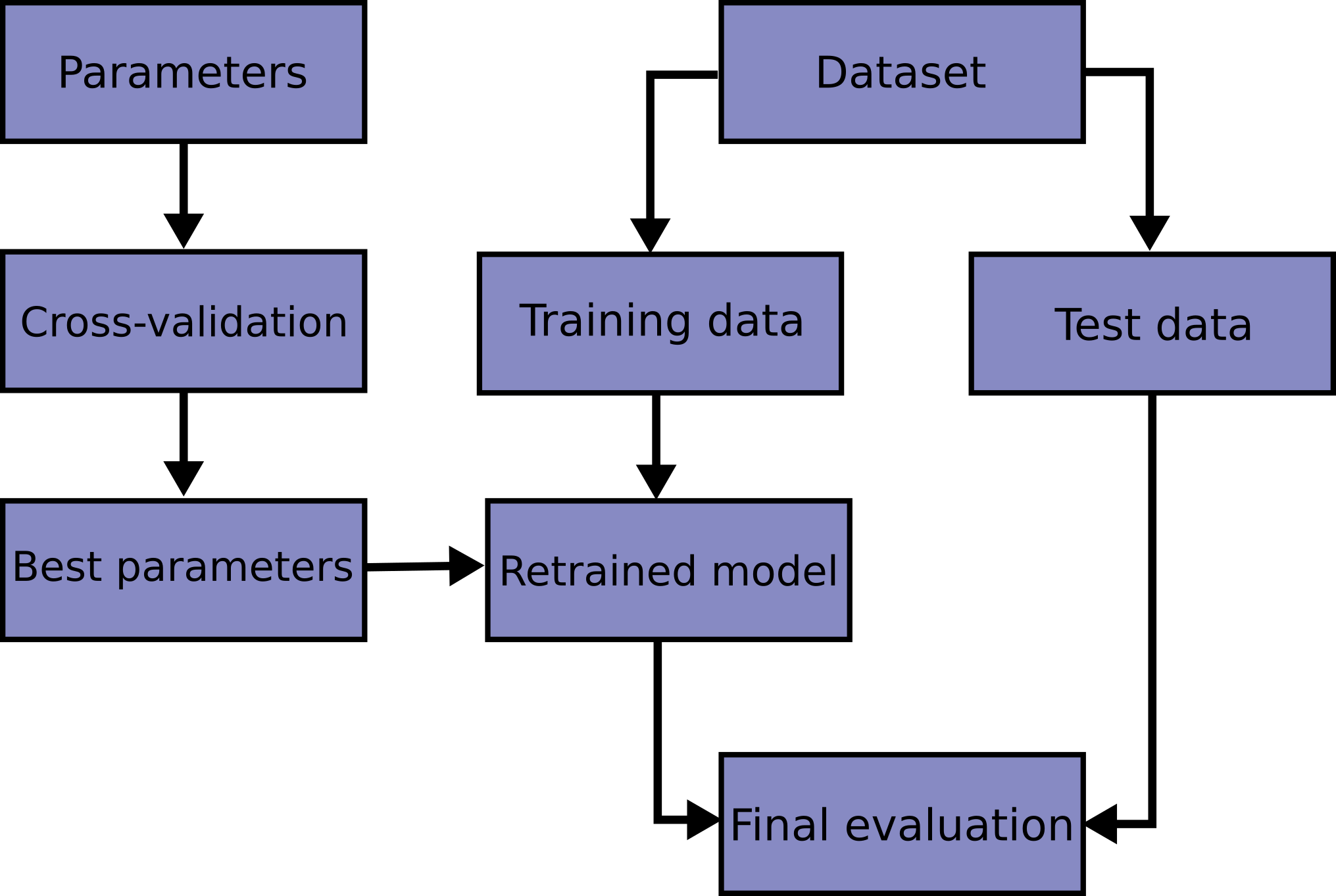
데이터를 분할하고 모델을 학습시킬 때, 다양한 매개변수를 필요로 합니다. 하지만 각각의 최적의 매개변수를 찾는 일은 아주 힘듭니다. 최고의 매개변수를 찾기 위한 여러 방법 중 하나가 바로 교차 검증입니다.
정의

이것은 먼저, 훈련 데이터세트를 Fold라고 하는 단위로 k개를 무작위로 나눕니다. 이것은 데이터 양이 충분치 않을 때, 성능 측정의 신뢰도를 높이기 위해 사용됩니다. Evaluating estimator performance. 이는 Grid Search와 함께 최적의 모델 parameter를 찾는 방법입니다.
순서
- 데이터를 k개의 Group으로 나눕니다. (Ramdomly)
- 한 그룹을 학습에 사용합니다.
- 다른 그룹을 사용하여 Test 및 성능을 평가합니다.
- 2,3번 과정을 k번 반복합니다.
- 모든 결과의 평균을 측정합니다.
교차 검증 반복자(Cross Validation iterators)
반복자의 선정은 데이터 세트의 모양과 구조에 따라 신중하게 선택이 되어야 합니다. 일반적으로 독립적인지, 동일한 분포인지를 보게 됩니다.
- 데이터가 독립적이고 동일한 분포를 가진 경우
- KFold, RepeatedKFold, LeaveOneOut(LOO), LeavePOutLeaveOneOut(LPO)
- 동일한 분포가 아닌 경우
- StratifiedKFold, RepeatedStratifiedKFold, StratifiedShuffleSplit
- 그룹화된 데이터의 경우
- GroupKFold, LeaveOneGroupOut, LeavePGroupsOut, GroupShuffleSplit
- 시계열 데이터의 경우
- TimeSeriesSplit
데이터가 독립적이고 동일한 분포를 가진 경우
-
KFold
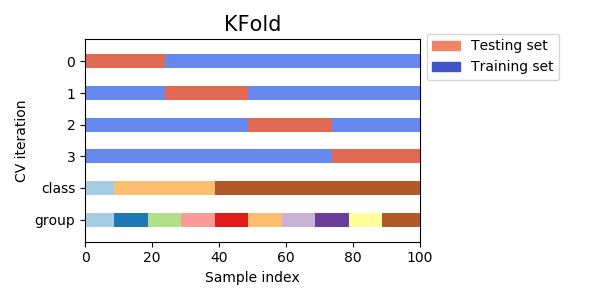
모든 데이터를 Fold라고 불리는 그룹으로 나누고 이를 split 하여 데이터 자체에서 훈련 데이터, 테스트 데이터를 반복적으로 선정합니다.
import numpy as np from sklearn.model_selection import KFold X = ["a", "b", "c", "d"] kf = KFold(n_splits=2) for train, test in kf.split(X): print("%s %s" % (train, test)) [2 3] [0 1] [0 1] [2 3]위의 코드에서는 인덱스 0, 1, 2, 3을 두 개씩 fold로 나누게 됩니다. [0 1]을 하나의 fold, [2 3]을 하나의 fold로 나누고 각각을 훈련과 테스트 세트로 반복합니다.
-
RepeatedKFold
KFold를 n번 반복하는 반복자입니다. 각 반복마다 다른 분할을 생성하여 진행합니다.
import numpy as np from sklearn.model_selection import RepeatedKFold X = np.array([[1, 2], [3, 4], [1, 2], [3, 4]]) random_state = 12883823 rkf = RepeatedKFold(n_splits=2, n_repeats=2, random_state=random_state) for train, test in rkf.split(X): print("%s %s" % (train, test)) [2 3] [0 1] [0 1] [2 3] [0 2] [1 3] [1 3] [0 2] -
LeaveOneOut(LOO)
간단한 교차 유효성 검사를 위한 반복자입니다. 하나의 데이터만을 테스트 데이터로 사용합니다. 데이터가 적을 때 데이터 낭비를 막는 방법입니다.
from sklearn.model_selection import LeaveOneOut X = [1, 2, 3, 4] loo = LeaveOneOut() for train, test in loo.split(X): print("%s %s" % (train, test)) [1 2 3] [0] [0 2 3] [1] [0 1 3] [2] [0 1 2] [3]해당 방법은 샘플 기준 k가 n에 비해 너무 작을 때 오히려 더 비싼 계산 방식입니다. 또한, 가끔씩 높은 분산 결과를 나타납니다.
-
LeavePOutLeaveOneOut(LPO)
LOO 반복자와 KFold를 섞은 방식의 반복자로서, KFold와 아주 유사한 방식입니다.
from sklearn.model_selection import LeavePOut X = np.ones(4) lpo = LeavePOut(p=2) for train, test in lpo.split(X): print("%s %s" % (train, test)) [2 3] [0 1] [1 3] [0 2] [1 2] [0 3] [0 3] [1 2] [0 2] [1 3] [0 1] [2 3] -
ShuffleSplit

데이터를 먼저 섞은 후에 Fold를 분할하는 방식입니다. random_state를 통하여 난수를 제어할 수 있습니다. KFold의 대안으로 좀 더 세밀한 반복자를 형성하는 방식입니다.
from sklearn.model_selection import ShuffleSplit X = np.arange(10) ss = ShuffleSplit(n_splits=5, test_size=0.25, random_state=0) for train_index, test_index in ss.split(X): print("%s %s" % (train_index, test_index)) [9 1 6 7 3 0 5] [2 8 4] [2 9 8 0 6 7 4] [3 5 1] [4 5 1 0 6 9 7] [2 3 8] [2 7 5 8 0 3 4] [6 1 9] [4 1 0 6 8 9 3] [5 2 7]
동일한 분포가 아닌 경우
-
StratifiedKFold

계층을 가진 Fold를 리턴하는 KFold의 변형된 반복자입니다. 각각 비율이 다른 클래스의 비율을 유지하면서 훈련과 테스트 세트를 분류합니다.
from sklearn.model_selection import StratifiedKFold, KFold import numpy as np X, y = np.ones((50, 1)), np.hstack(([0] * 45, [1] * 5)) skf = StratifiedKFold(n_splits=3) for train, test in skf.split(X, y): print('train - {} | test - {}'.format( np.bincount(y[train]), np.bincount(y[test]))) train - [30 3] | test - [15 2] train - [30 3] | test - [15 2] train - [30 4] | test - [15 1] kf = KFold(n_splits=3) for train, test in kf.split(X, y): print('train - {} | test - {}'.format( np.bincount(y[train]), np.bincount(y[test]))) train - [28 5] | test - [17] train - [28 5] | test - [17] train - [34] | test - [11 5]위의 코드는 0 클래스 45개, 1 클래스 5개로 이루어진 데이터를 생성하여 Fold로 훈련, 테스트 세트를 나누는 코드입니다. 훈련 및 테스트 데이터 세트를 기존 데이터 비율 9:1과 비슷하게 유지하는 것을 확인할 수 있습니다.
-
RepeatedStratifiedKFold
위의 StratifiedKFold 방식을 n번 반복하는 방식입니다.
-
StratifiedShuffleSplit

ShuffleSplit의 변형으로 계층화된 클래스의 비율을 유지하면서 Shuffle 하는 방식입니다.
그룹화된 데이터의 경우
-
GroupKFold

KFold의 변형된 방식으로, 동일한 한 클래스가 테스트 또는 훈련 데이터 세트에 한 번에 들어가지 않도록 합니다. 각각 클래스들의 특징을 살리기 위한 방식입니다.
-
LeaveOneGroupOut
하나의 클래스를 제외시키고 GroupKFold 하는 방식입니다. 이 방식은 시간과 관련된 데이터에서 많이 사용됩니다.
from sklearn.model_selection import LeaveOneGroupOut X = [1, 5, 10, 50, 60, 70, 80] y = [0, 1, 1, 2, 2, 2, 2] groups = [1, 1, 2, 2, 3, 3, 3] logo = LeaveOneGroupOut() for train, test in logo.split(X, y, groups=groups): print("%s %s" % (train, test)) [2 3 4 5 6] [0 1] [0 1 4 5 6] [2 3] [0 1 2 3] [4 5 6] -
LeavePGroupsOut
하나가 아닌 P개의 클래스를 제외하는 방식으로, LeaveOneGroupOut과 유사합니다.
-
GroupShuffleSplit

ShuffleSplit과 GroupKFold를 합친 방식입니다. 클래스의 치우침을 방지하고, 랜덤 분할하는 방식입니다.
from sklearn.model_selection import GroupShuffleSplit X = [0.1, 0.2, 2.2, 2.4, 2.3, 4.55, 5.8, 0.001] y = ["a", "b", "b", "b", "c", "c", "c", "a"] groups = [1, 1, 2, 2, 3, 3, 4, 4] gss = GroupShuffleSplit(n_splits=4, test_size=0.5, random_state=0) for train, test in gss.split(X, y, groups=groups): print("%s %s" % (train, test)) [0 1 2 3] [4 5 6 7] [2 3 6 7] [0 1 4 5] [2 3 4 5] [0 1 6 7] [4 5 6 7] [0 1 2 3]
시계열 데이터의 경우
-
TimeSeriesSplit

그룹을 나누는 것까진 다른 것들과 동일합니다. 대신, 시계열 데이터는 연속적인 데이터를 유지해야 하므로, 앞에서 훈련시킨 것들을 다음에도 연속적으로 사용합니다. 훈련 데이터 세트를 키워나가는 식으로 진행합니다.
from sklearn.model_selection import TimeSeriesSplit X = np.array([[1, 2], [3, 4], [1, 2], [3, 4], [1, 2], [3, 4]]) y = np.array([1, 2, 3, 4, 5, 6]) tscv = TimeSeriesSplit(n_splits=3) print(tscv) TimeSeriesSplit(max_train_size=None, n_splits=3) for train, test in tscv.split(X): print("%s %s" % (train, test)) [0 1 2] [3] [0 1 2 3] [4] [0 1 2 3 4] [5]
사용법
-
cross_val_score()
-
estimator: estimator
- 학습을 할 모델을 의미합니다.
-
x: array
- 학습시킬 훈련 데이터 세트입니다.
-
y: array
- 학습시킬 훈련 데이터 세트의 Label입니다.
-
scoring: string or None
- 각 모델에서 사용할 평가 방법입니다.
- 교차 검증은 utility function을 사용합니다. 그래서 더 큰 값이 좋은 결과라는 의미입니다.
- 위와 같은 이유로 Regression 모델에서는 MSE를 얻기 위해 주로 'neg_mean_squred_error'값을 사용합니다. (0으로 갈수록 좋은 점수)
-
cv: int or kfold
-
Cross-Validation generator
-
Fold의 수를 의미합니다.
-
앞서 정리한 교차 검증 반복자를 사용합니다. 또는, custom 한 fold를 생성하는 iterator를 만들어서 주어도 됩니다.
cv = ShuffleSplit(n_splits=5, test_size=0.3, random_state=0)
cross_val_score(clf, X_train, Y_train, cv=cv)
-
-
scores: returns, array
-
scoring을 사용하여 평가한 점수를 각각 교차 검증을 반복 시마다 기록하여 돌려줍니다.
cross_score = cross_val_score(lin_reg, X_train, Y_train, scoring='neg_mean_squared_error', cv=10) rmse_score = nq.sqrt(-cross_score) rmse_mean = rmse_score.mean() rmse_std = rmse_score.std()
-
평가 결과는 neg_mean_squared_error값으로 리턴되도록 선언한 코드이며, 이를 양수 값으로 바꾸고 rmse를 계산한 코드입니다.
mean()과 std()를 사용하여 평균값과 표준편차를 확인할 수 있습니다.
-
-
cross_validate()
다중 평가 지표는 모델을 평가할 때 여러 개의 지표를 사용하여 모델을 평가한다는 의미입니다. Scikit-learn은 0.19 버전부터 cross_validate() 함수를 통해 다중 평가 지표 기능을 제공합니다. 다중 평가 지표는 GridSearch에서도 사용 가능합니다.
-
cross_val_score와 파라미터는 유사합니다.
-
cross_val_score()와 마찬가지로 scoring 매개변수를 통하여 평가 지표를 지정합니다. 다중 평가 지표를 사용하고자 한다면 리스트로 작성하여 전달하면 됩니다.
-
return_train_score: cross_val_score와 다르게 테스트 폴드 점수뿐 아니라 훈련 폴드에 대한 점수를 리턴 받을 수 있습니다. 해당 매개변수는 훈련 폴드의 점수를 받을지 여부를 설정하는 변수입니다.
from sklearn.model_selection import cross_validate cross_validate(SVC(gamma='auto'), X_train, y_train, scoring=['accuracy', 'roc_auc'], return_train_score=True)SVC를 모델로 사용하였고, scoring 매개변수에서 리스트로 여러 평가 지표를 전달합니다. 리스트의 지표가 하나이면, cross_val_score()와 같은 기능을 합니다. return_train_score에서는 훈련 Fold에 대한 점수를 받는지 여부입니다. 결과는 아래와 같은 예제 형식으로 나타납니다.
{'fit_time': array([0.07761502, 0.07732582, 0.07719207]), 'score_time': array([0.06746364, 0.06803942, 0.06800795]), 'test_accuracy': array([0.90200445, 0.90200445, 0.90200445]), 'test_roc_auc': array([0.99657688, 0.99814815, 0.99943883]), 'train_accuracy': array([1., 1., 1.]), 'train_roc_auc': array([1., 1., 1.])}훈련 및 테스트에 걸린 시간과 각각 지표마다의 점수를 딕셔너리 형태로 반환합니다.
또한 아래의 코드와 같이 딕셔너리 형태로 scoring을 전달 가능합니다. 결과는 딕셔너리의 키 값에 맞게 바뀌어서 전달됩니다.
cross_validate(SVC(gamma='auto'), X_train, y_train, scoring={'acc':'accuracy', 'ra':'roc_auc'}, return_train_score=False, cv=3)
-
다음 포스팅에는 이어서 Grid Search에 대한 내용을 이어서 포스팅하겠습니다!
Reference
Cross-Validation Scikit-Learn Document(Code & Figure):
https://scikit-learn.org/stable/modules/cross_validation.html
cross_val_score():
https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.cross_val_score.html#sklearn.model_selection.cross_val_score
cross_validate():
https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.cross_validate.html#sklearn.model_selection.cross_validate
텐서 플로우 블로그:
https://tensorflow.blog/tag/cross_val_score/
반응형
'IT > Machine Learning' 카테고리의 다른 글
| 머신러닝 (7) - Regression(회귀) (4) | 2020.02.12 |
|---|---|
| 머신러닝 (6) - Fine Tuning Model (2) | 2020.02.12 |
| 머신러닝 (4) - ML 모델 생성과 훈련, 예측, 평가 (2) | 2020.01.28 |
| 머신러닝 (3) - 데이터 전처리 (0) | 2020.01.22 |
| 머신러닝 (2) - ML프로젝트를 위한 데이터 선택 및 준비 (0) | 2020.01.21 |




