고정 헤더 영역
상세 컨텐츠
본문

Writer : Harim Kang

추천 시스템은 이제 4차 산업 시대에서 필수적인 요소입니다. 이미지 또는 영상과 같은 콘텐츠 추천부터 시작해서, 쇼핑, 광고 노출, 검색어 노출, SNS 등등 모든 분야에서 추천이 들어가지 않는 곳이 없을 정도입니다.

심지어, 최근의 추천 알고리즘들은 소름돋게 잘 맞추는 경우가 생길 정도입니다. 유튜브의 '알 수 없는 추천 알고리즘'에 의해 연관성이 없어 보이는 영상을 보는 시청자가 꽤 상승하는 것도, 이러한 연관성이 없어 보이는 영상을 생각보다 잘 보는 시청자가 늘어나는 것도 어찌 보면, 나 자신보다 추천 알고리즘이 내 취향을 잘 아는 것 아닐까라는 생각이 들 정도입니다.
추천 이란?

추천은 예측입니다. 추천은 상대방이 선호할 만한 결과를 제안하는 것입니다. 사용자에게 정보를 제공했을 때 과연 어떤 반응을 보일 것인가를 예측하는 것 또한 추천이 할 일입니다. 긍정적인 반응을 끌어올 만한 것이 추천의 대상입니다.
추천은 결과를 얻고자 하는 대상을 분석하는 일부터 시작합니다. 그것은 대상에게 주고자 하는 것을 분석하는 일이 될 수도 있고, 그 대상을 분석하는 일이 될 수도 있습니다.
추천 시스템은 이러한 추천을 데이터적이고, 컴퓨터적으로 옮겨온 것입니다. 또한, 데이터의 양이 아주 많아지고 유의미한 데이터를 분석하는 기법이 발달함에 따라 추천 시스템을 구축할 수 있게 되었습니다.
하지만 추천은 데이터적으로 완전하게 맞는 정답이 나오기는 힘이 듭니다. 왜냐하면, 결과로 보여준 것들의 대부분은 사용자가 경험하지 못한 것들에 대한 것이기 때문입니다. 이는 결과를 받은 후에, 평가로 확인하여야 비로소 정확한지 아닌지를 따질 수 있는 것입니다.

추천이라는 분야도 머신러닝 분야에 속하게 되었습니다. 데이터와 관련된 분석 및 예측을 주로 이용하기 때문입니다. 현재의 추천 시스템은 예측과 피드백 데이터를 바탕으로 모델 성능을 평가합니다. 제 생각에는 추천 시스템에서 더 나은 평가를 받기 위해서는 적절한 피드백을 받아야 하며, 이 피드백이 아주 중요하다고 생각합니다.
추천 시스템의 목적
- 관련성 : 사용자에게 적합한 아이템을 추천
- 참신성 : 사용자가 전에 본 적 없던 새로운 아이템을 추천
- 우연성 : 사용자에게 다소 의외이거나 놀라움을 주는 아이템을 추천
추천 시스템의 원리
아주 간단하게 추천의 원리에 대해 예시로 설명드리겠습니다.
- 20대 여성들은 분위기 좋은 카페를 선호한다.
- 20대 여성들을 대상으로 설문조사를 하여 나온 데이터 분석 결과라고 볼 수 있습니다.
- 이때, 어떤 사용자가 20대 여성일 때, 카페를 찾고자 한다면 시스템은 평범한 카페보다 상대적으로 분위기 좋은 근처의 카페를 추천할 수 있습니다. 1번을 근거로 말입니다.
- 20대 남성들은 액션이 많고 화려한 볼거리의 영화를 많이 보더라
- 20대 남성이라는 타깃을 분석한 결과라고 생각하고,
- 어떤 사용자가 20대 남성이면 위를 근거로 액션 영화를 추천할 가능성이 높다는 것이 바로 추천의 원리입니다.
위와 같은 예시들도 다 추천입니다. 하지만 위의 예시들은 문제점이 많습니다. 인기, 대중성에 기반하여 일반화된 추천을 제공한다는 점이 첫 번째입니다. 또한 개개인의 성향을 모르고, 큰 타깃 범위만으로 추천을 하는 것입니다. 추천 결과에 대한 만족도가 떨어질 수밖에 없는 이유입니다.
위의 예시와 같은 추천이 이루어지다가, 더 다양한 데이터 수집이 가능해지고, 개인의 데이터가 아주 많아지게 됩니다. 또한, 소비자의 욕구들이 아주 다양해졌습니다. 이것에 대응하기 위해서 맞춤형 정보를 제공하고자 합니다. 기존의 추천 시스템보다 더 개인화되고 정확한 추천을 하고자 하는 것입니다. 그래서 추천 알고리즘이 나오게 됩니다.
추천 알고리즘의 변화
기존의 단순한 알고리즘에서 다양한 대응을 할 수 있는 시스템의 구축을 위해 알고리즘이 더 복잡해집니다.
어제의 데이터를 분석하여 내일의 사용자의 행동을 예측하는 머신 러닝 알고리즘으로 가게 되는 것이죠. 이것은 다양한 데이터 소스를 활용하여 소비자의 취향과 원하는 것을 추론하고자 합니다. 사용자와 아이템 간의 상호작용을 점수로서 계산하고, 점수가 높은 것을 추천하는 것입니다.
대표적인 예가, Content-based와 Collaborative Filtering입니다.
추천 시스템의 대표적인 모델
- Prediction Version
- Matrix Completion Problem
- 사용자와 아이템 간의 평가 점수를 예측하는 것입니다.
- m명의 user, n개의 item이 있을 때, m x n matrix를 계산하는 방식입니다.
- Ranking Version
- Top-k Recommendation Problem
- 특정 유저에게 k개의 적합한 아이템을 추천해주는 방식입니다.
Content-based Recommenders
간단하게 말하면, 특정 아이템에 기초하여 비슷한 아이템을 추천해준다는 것입니다.
- 아이템끼리의 유사도를 측정합니다.
- 아이템의 metadata를 사용합니다.
- Ex) 장르, 감독, 묘사, 배우, etc..
- 만약 사용자가 특정 아이템을 선호한다고 하면, 해당 아이템과 유사한 아이템을 추천하는 방식입니다.

특징은 사람들 간을 비교하지 않고, 아이템 특성만을 비교한다는 점입니다. 사용자가 적은 초반의 추천 시스템의 경우 대부분 Content-based recommender를 사용합니다.
장단점
- 장점
- 다른 사용자의 영향을 받지 않는다.
- 새로운 아이템에 대해서도 추천이 가능하다.
- 추천을 설명하기 쉽다.
- 단점
- 새로운 유저에게 추천이 불가능하다.
- 소리, 영상, 이미지 등의 콘텐츠로부터 추천을 위한 metadate, 특징을 추출하기가 어렵다.
추천의 순서
- 아이템의 분류를 통해 콘텐츠를 분석합니다.
- 각각의 유저의 선호를 대표하는 유저의 profile을 학습합니다.
- 아이템의 분류 & 사용자 선호도에 따라 각각의 유저를 위한 추천 리스트를 생성합니다.
ML Techniques
사용되는 머신러닝 테크닉은 아래와 같습니다.
- KNN Classification (nearest neighbor)
- Linear Classification
콘텐츠 묘사
- 구조화된 콘텐츠
- 구조화되지 않은 콘텐츠
- Ex) keyword
- 'Bag or Words'방식 또는 'TF/IDF'방식을 사용한다. 단어의 중요성을 검토하여 사용한다.
아이템 유사도
- Cosine Similarity
- 그 외 다른 적합한 유사도
Collaborative Filtering Recommenders
사용자 그룹이 형성되어 있고, 그들 간의 평가 점수와 선호도를 고려하여, 사용자의 예측 점수와 선호도가 결정됩니다. 한마디로, 사용자와 비슷한 다른 사용자를 찾아서 그 사용자는 어떤 평가를 했는지를 살펴보는 방식입니다.
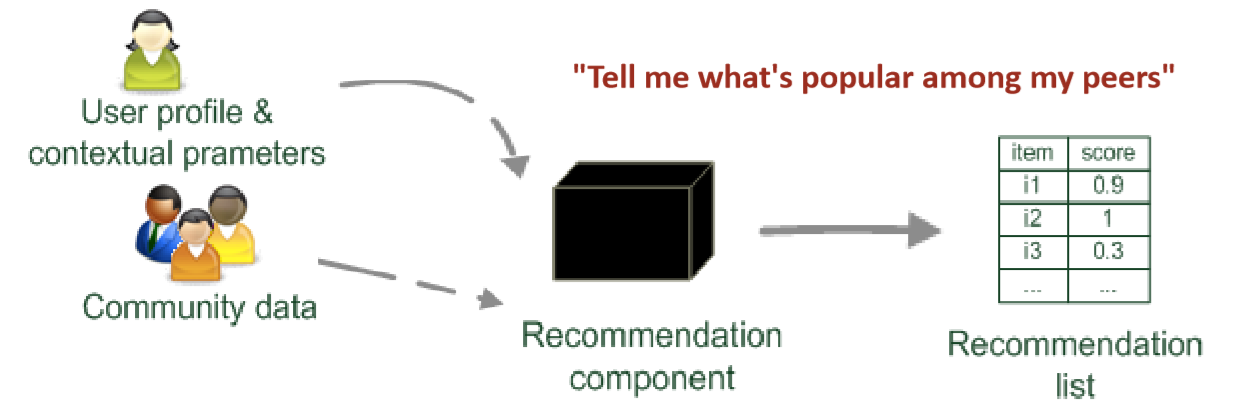
사용자가 어느 정도 형성이 되어있고, 데이터가 존재할 때 사용 가능한 추천 알고리즘 방식입니다.
장단점
- 장점
- 어떠한 아이템에 대해서도 추천이 가능하다. (아이템의 특성에 의존하지 않는다.)
- 단점
- 평가되지 않은 아이템에 대해 추천을 하지 않는다. (new-item problem)
- 보통 가장 인기 있는 아이템을 추천한다.
- 비슷한 유저 군이 존재하는 사용자 그룹이 어느 정도 숫자 이상 필요하다. (cold start problem for new users)
작동 방식
- Input
- 주어진 유저-아이템 간의 평가점수 matrix
- Output
- 특정 아이템에 대한 선호도 예측 점수
- top-N 추천 리스트
두 가지 방식의 CF
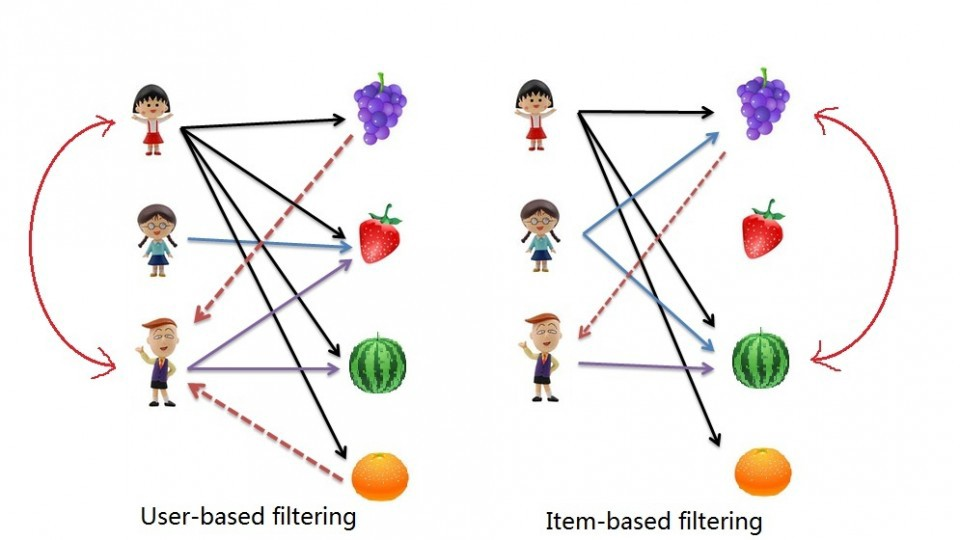
-
User-Based Filtering
-
유저들의 평가 점수를 바탕으로, 예측하고자 하는 유저의 점수를 예측하는 방식
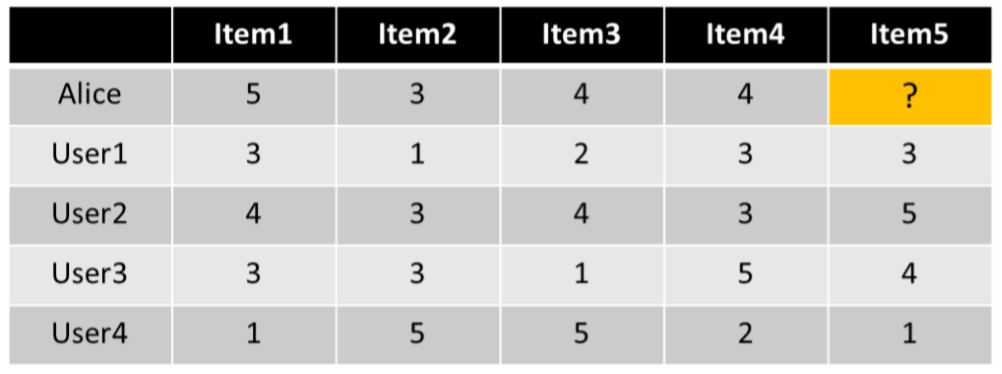
User-based CF -
Steps
-
유저 간의 유사성 계산 (Pearson Correlation)

Similarity Calculation -
예측
-
-
장단점
- 장점
- 구현하기 쉽다.
- 문맥이 독립적이다.
- contents-based에 비해 정확하다.
- 단점
- 희소성 : 평가를 하는 사용자가 적다.
- 확장성 : 사용자 그룹이 커질수록 비용이 비싸다.
- Cold Start : 신규 사용자에게 추천이 힘들다.
- 장점
-
-
Item-based Filtering
-
사용자 그룹을 사용하여, 관계를 판단하기에 CF에 포함됩니다.
-
아이템 사이에 유사성을 판단하여 예측을 합니다. (KNN Step을 건너뛴다.)
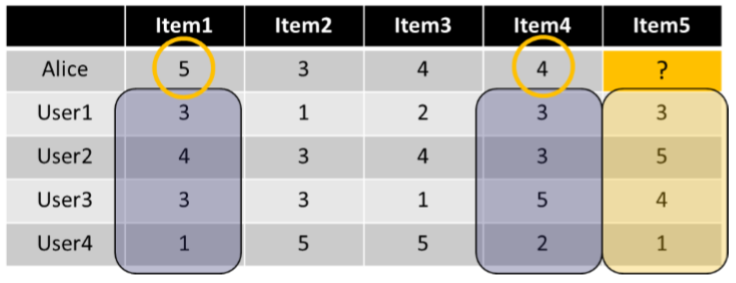
Item-based CF -
User-based보다 더 좋은 성능을 보여줍니다.
-
Hybrid Recommender Systems
데이터와 상황에 따라 Content-based와 Collaborative filtering을 적절히 섞어서 사용하는 방식입니다.
Reference
Recommend 이미지 : Samsung Newsroom
2 Types of Collaborative Filtering : https://medium.com/@cfpinela/recommender-systems-user-based-and-item-based-collaborative-filtering-5d5f375a127f
feedback image : https://www.researchgate.net/figure/The-sequential-recommendation-process-After-the-RS-recommends-an-item-the-user-gives_fig4_311513879
2탄에서는 세계적인 기업들의 추천 서비스를 분석하는 포스팅을 올릴 예정입니다. (포스팅 완료!)
또한, 추천 시스템 기획, 설계, 구현을 하는 프로젝트를 추후 예정하고 있습니다.
2020/01/14 - [IT/Machine Learning & Deep Learning] - 추천 시스템 (2) - 실제 시스템 분석
추천 시스템 (2) - 실제 시스템 분석
Writer : Harim Kang 추천 시스템관련 두번째 포스팅입니다. 추천 시스템의 개요와 알고리즘을 알고싶으시다면 아래의 포스팅을 봐주시길 바랍니다. 현 포스팅은 페이스북, 넷플릭스, 왓챠, 아마존 등에서 사용하..
davinci-ai.tistory.com
반응형
'IT > Machine Learning' 카테고리의 다른 글
| 머신러닝 (4) - ML 모델 생성과 훈련, 예측, 평가 (2) | 2020.01.28 |
|---|---|
| 머신러닝 (3) - 데이터 전처리 (0) | 2020.01.22 |
| 머신러닝 (2) - ML프로젝트를 위한 데이터 선택 및 준비 (0) | 2020.01.21 |
| 추천 시스템 (2) - 실제 시스템 분석 (3) | 2020.01.14 |
| 머신러닝 (1) - 머신러닝을 사용하는 이유와 분류 그리고 문제점 (0) | 2020.01.05 |




