고정 헤더 영역
상세 컨텐츠
본문

Writer: Harim Kang
머신러닝 - 2. End-to-End Machine Learning Project (1)
해당 포스팅은 머신러닝의 교과서라고 불리는 Hands-On Machine Learning with Scikit-Learn & Tensor flow 책을 학습하며 정리하고, 제 생각 또한 함께 포스팅한 내용입니다. 아래의 포스팅에 이어진 내용입니다.
2020/01/05 - [IT/Machine Learning & Deep Learning] - 머신러닝 (1) - 머신러닝을 사용하는 이유와 분류 그리고 문제점
머신러닝 (1) - 머신러닝을 사용하는 이유와 분류 그리고 문제점
Writer: Harim Kang 머신러닝 - 1. The Machine Learning Landscape 해당 포스팅은 머신러닝의 교과서라고 불리는 Hands-On Machine Learning with Scikit-Learn & Tensorflow 책을 학습하며 정리하고, 제 생각..
davinci-ai.tistory.com
https://learning.oreilly.com/library/view/hands-on-machine-learning/9781491962282/ch02.html의 내용과 제 조사 및 생각을 함께 정리한 포스팅입니다.
오늘의 포스팅은 Chapter 2. End-to-End Machine Learning Project 단원이며, 해당 단원은 California Housing Prices Dataset을 예제로 삼아 전체적인 흐름을 살펴보기 위하여 머신러닝 프로젝트의 단계 순서로 한번 진행해 보는 단원입니다. 목표 설정 및 데이터 선정부터 데이터 분석, 정제, 학습, 예측, 최적화의 순서로 하나의 예제를 진행합니다. 저는 예시 코드에 중점을 두기 보다, 각각 단계에서 필요한 정보들을 간단히 정리하였습니다.

데이터 세트를 얻을 수 있는 방법, 입문자를 위한 데이터 세트 추천, Scikit-Learn 라이브러리의 다양한 메서드 정리를 포함한 포스팅입니다.
머신러닝 프로젝트의 단계
- 목표 설정
- 데이터 준비
- 데이터 시각화
- 상관관계 분석
- 데이터 정제
- Training with ML Algorithm : 알고리즘 선정 및 훈련
- Fine-tuning the Model : 평가에 따른 최적 모델을 찾기 위한 조정
- Launching, monitoring and maintaining the model : 훈련된 모델의 사용, 모니터링, 유지 보수
목표 설정
데이터 세트를 얻을 수 있는 곳
-
Kaggle Datasets : https://www.kaggle.com/datasets
-
the UC Irvine Machine Learning Repository : http://archive.ics.uci.edu/ml/index.php
-
Registry of Open Data on AWS : https://registry.opendata.aws/
-
한국 공공데이터 포털 : https://www.data.go.kr/
-
Pathmind AI Wiki : https://pathmind.com/kr/wiki/open-datasets
-
AI Hub (국내) : http://aihub.or.kr/
-
DataPortals.org (Meta Portals) : http://dataportals.org/
-
Open Data Monitor (Meta Portals) : https://opendatamonitor.eu/frontend/web/index.php?r=dashboard%2Findex
-
Quandl (Meta Portals) : https://www.quandl.com/
-
Wikipedia의 ML Dataset List (listing many popular open data repositories) : https://en.wikipedia.org/wiki/List_of_datasets_for_machine-learning_research
-
Reddit Datasets (listing many popular open data repositories) : https://www.reddit.com/r/datasets/
-
그 외의 다양한 Data를 얻을 수 있는 곳들 : https://www.quora.com/Where-can-I-find-large-datasets-open-to-the-public
입문자를 위한 데이터 세트 추천
Machine Learning 프로젝트를 처음 해보는 사람들을 위한 추천 데이터 세트입니다. 기본적으로 많은 예제가 존재하는 데이터 세트부터, 상대적으로 다루기 쉬운 kaggle의 데이터 세트를 선정하였습니다.
-
California Housing Prices Dataset : 캘리포니아 부동산 가격 데이터 세트 (1990) - Regression
https://raw.githubusercontent.com/ageron/handson-ml/master/datasets/housing/housing.tgz
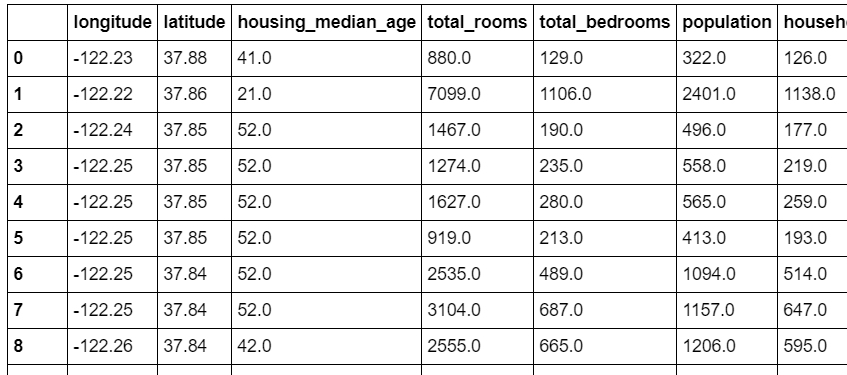
아래의 Iris 데이터 세트와 함께 머신러닝의 입문을 위하여 많이 사용되는 데이터 세트입니다. 다양한 데이터 정보를 통해 집 값을 예측하는 Regression이 적합한 데이터 세트입니다. 해당 데이터 세트를 이어지는 포스팅에 예제로 사용할 것입니다.
-
Iris Dataset : 붓꽃 데이터 세트 - Classification
해당 데이터 세트는 sklearn 라이브러리에서 기본적으로 제공해주는 데이터 세트입니다. 입문자들이 가장 많이 사용하는 Classification에 적합한 데이터 세트입니다.
아래의 코드로 데이터를 불러옵니다.
from sklearn import datasets iris = datasets.load_iris() -
Mushroom Dataset : 버섯 데이터 세트 (Kaggle) - Classification
https://www.kaggle.com/uciml/mushroom-classification

해당 데이터 세트는 class항목에서 독이 있는지 (p), 없는지(e)로 버섯을 구분하는 Classification이 적합한 데이터 세트입니다.
-
Medical Cost Personal Dataset : 개인별 특징에 따른 의료비 데이터 세트 (Kaggle) - Regression
https://www.kaggle.com/mirichoi0218/insurance/data

해당 데이터 세트를 보면, Charges라는 병원 진료비가 나와있습니다. age, bmi, children 수에 따른 진료비를 예측하는 Regreesion이 적합한 데이터 세트입니다.
-
Red & White Wine Dataset : 레드 & 화이트 와인 데이터 세트 (Kaggle) - Classification
https://www.kaggle.com/numberswithkartik/red-white-wine-dataset
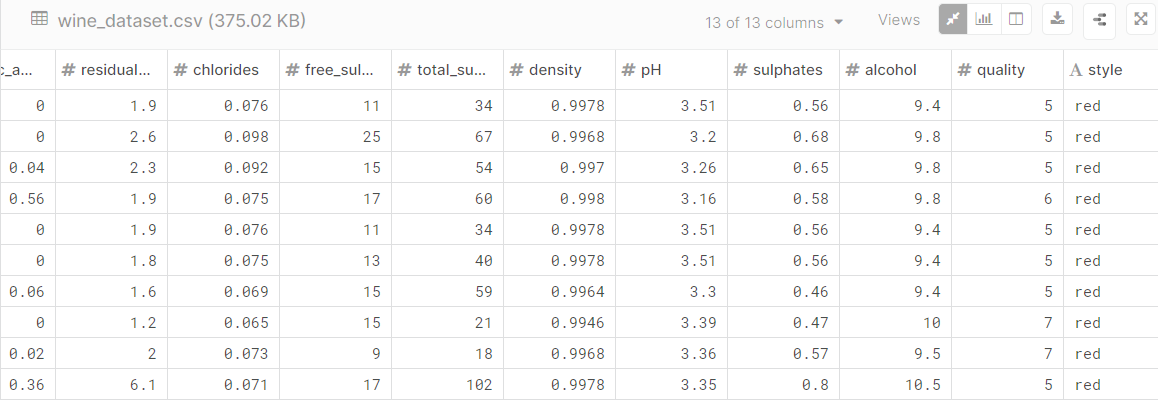
해당 데이터 세트를 보자면 Style항목에서 Red와 White 두 가지 종류가 있습니다. 그 앞의 데이터들을 토대로 Red 또는 White를 예측하는 Classification에 적합한 데이터 세트입니다.
Kaggle 데이터 세트들은 url을 통하여 코드로 다운 또는 직접 페이지에 가서 데이터 세트를 다운로드하면 됩니다. 모두 같은 방식으로 csv파일을 불러오면 됩니다.
데이터 세트를 살펴보고 목표를 설정하면 됩니다. 데이터 세트에 따라 분류(Classification)가 적합한지 회귀(Regression)가 적합한지를 확인하고, 이를 목표로 설정하는 것이 쉽습니다. 간단하게 분류와 회귀를 구분 짓자면, 분류는 Class로 output이 나오는 것을 의미하고, 회귀는 어떠한 값을 예측하고자 할 때 사용합니다. 위의 데이터 세트를 살펴보면 쉽게 확인이 가능합니다.
성능 측정 선택
목표에는 어떤 데이터를 Output으로 보여주고자 하는지, 어떤 평가 기준을 사용하여 모델의 성능을 보여주고자 하는 지를 정해야 합니다.
대표적인 두 가지 평가 지표를 살펴보겠습니다.
-
Mean Absolute Error (MAE) :
실제 예측한 값과 모델이 예측한 값의 오차의 평균을 의미하는 지표입니다. 0에 가까울수록 오차의 평균이 작다는 의미로서 학습시킨 모델이 더 정확(더 좋은 성능을 낸다)하다고 생각하시면 됩니다.
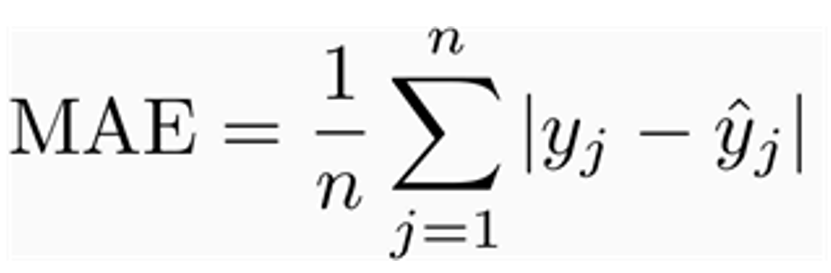
Mean Absolute Error (MAE) Formula 
-
Root Mean Square Error (RMSE) : Regression을 사용하여 예측할 때 가장 대표적으로 성능을 평가하는 지표입니다. 이것은 예측값과 실제값을 뺀 오차의 평균을 살펴보는 지표로서 이 평균값에 제곱근을 실제 지표로 사용합니다.
해당 값 또한 MAE와 마찬가지로 0에 가까울수록 좋은 성능을 내는 모델이라는 것을 알 수 있습니다.

Root Mean Square Error (RMSE) Formula 이는 평균 제곱근 편차(표준 편차)와 같은 공식으로 사용됩니다.
사실 RMSE값은 MSE라는 오차 제곱의 평균값을 루트 한 값입니다. scikit-learn 라이브러리에서는 MSE를 계산하는 메서드를 제공합니다. 이를 이용하여 sqrt(루트)하면 RMSE값을 계산할 수 있습니다.
import numpy as np from sklearn.metrics import mean_squared_error mse = mean_squared_error(actual_value, predicted value) rmse = np.sqrt(mse) -
RMSE vs MAE
- 비슷한 점
- 두 측정값 모두 예측 오차의 평균을 사용한다는 점이 비슷합니다.
- 0부터 무한대의 값을 가집니다.
- 값이 낮을수록 좋다는 점이 있습니다.
- 다른 점
- RMSE는 상대적으로 큰 오차(Error)에 대해 높은 가중 치을 가집니다. (큰 Error에 대해 민감하다)
- 평균으로 나누기 전에 오차를 제곱하기 때문에 상대적으로 큰 오차에 대해 영향력이 큽니다.
- 큰 오차가 좋지 않은 경우에, RMSE값을 확인하는 것이 좋습니다.
- 반면에 MAE는 큰 오차에 대해 RMSE만큼 증가하지는 않습니다.
- RMSE는 상대적으로 큰 오차(Error)에 대해 높은 가중 치을 가집니다. (큰 Error에 대해 민감하다)
- 결론
- RMSE값은 큰 오류에 대해 치명적일 수 있습니다. (큰 오류에 대한 대비책으로서 RMSE값을 선택합니다.)
- MAE는 Formula 측면에서 RMSE에 비해 이해하기가 쉽고, 다른 문제점을 찾기에 용이하다.
- 비슷한 점
-
Assumptions 체크하기
Assumptions을 확인하고, 나열하는 것은 중요합니다. 이는 심각한 문제를 먼저 찾아낼 수 있습니다.
데이터 준비
데이터 준비과정은 아래의 순서로 진행됩니다.
-
Fetch data from server : 서버로부터 데이터를 가져옵니다.
California Housing Prices Dataset을 예로 들어서 설명하겠습니다. DOWNLOAD_ROOT는 데이터를 얻을 수 있는 경로를, HOUSING_URL는 실제 파일 주소를 뜻합니다. 아래는 서버에서 URL 주소의 tgz파일을 읽어와서 csv파일로 dataset을 생성하는 함수입니다.
import os import tarfile from six.moves import urllib # dataset이 존재하는 url 경로 DOWNLOAD_ROOT = "https://raw.githubusercontent.com/ageron/handson-ml/master/" HOUSING_PATH = os.path.join("datasets", "housing") HOUSING_URL = DOWNLOAD_ROOT + "datasets/housing/housing.tgz" #data를 다운하는 함수 작성 def fetch_housing_data(housing_url=HOUSING_URL,housing_path=HOUSING_PATH): if not os.path.isdir(housing_path): #dataset/housing 이라는 폴더가 없으면 os.makedirs(housing_path) # dir 생성 tgz_path = os.path.join(housing_path,"housing.tgz") urllib.request.urlretrieve(housing_url,tgz_path) #url주소에 가서 housing.tgz를 찾기 housing_tgz = tarfile.open(tgz_path) #파일을 열어서 housing_tgz.extractall(path=housing_path) #csv파일 생성 housing_tgz.close() fetch_housing_data() #서버에서 URL주소의 tgz파일을 읽어와서 csv파일을 dataset으로 생성 -
Load Data : 데이터를 불러와서 변수에 저장합니다.
import pandas as pd #dataset을 불러오는 함수작성 def load_housing_data(housing_path = HOUSING_PATH): csv_path = os.path.join(housing_path,"housing.csv") #csv파일의 위치 return pd.read_csv(csv_path) #csv파일을 read housing = load_housing_data() #read하여 변수에 저장 -
Data Structure를 살펴봅니다. hist라는 메서드는 데이터의 각각 항목을 시각화하여 보여줍니다.
import matplotlib.pyplot as plt housing.hist(bins=50, figsize=(20,15)) plt.show()
-
Training Set과 Testing Set을 나눕니다.
scikit-learn에서는 train_test_split()이라는 메서드를 제공하여 데이터를 훈련 데이터 세트와 테스트 데이터 세트로 나누어줍니다. test_size=0.2라는 의미는 20%를 Test dataset으로, 나머지 80%를 train dataset으로 나누겠다는 의미입니다.
from sklearn.model_selection import train_test_split train_set, test_set = train_test_split(housing, test_size=0.2, random_state=42)
데이터 시각화
데이터를 시각화하는 방법은 다양한 방법이 있습니다. Scattrplot을 이용하여 데이터를 흩뿌려서 시각화하는 방법, 특정 변수의 Density를 비교하여 시각화하는 방법 등의 다양한 방법이 있습니다. 해당 부분은 생략하겠습니다.
상관관계 분석
상관 계수(Correlation Coefficient)
두 변수 사이의 상대적인 위치 관계의 강도를 나타내는 값으로, 선형 상관관계(Linear Correlations)에서만 측정합니다. 쉽게 말해서 두 변수 간에 상관관계가 있는지를 판단하는 계수로서, x좌표와 y좌표 각각에 두 변수를 놓았을 때, 선형적인 관계를 보인다면 그것의 기울기를 의미합니다.
-
특징
-
선형 관계의 두 변수에서 측정이 가능합니다.
-
상관 계수의 범위는 -1에서 1 사이입니다.
-
1에 가까울수록, 강한 positive correlation(양의 상관관계)을 의미합니다.
-
-1에 가까울수록, 강한 negative correlation(음의 상관관계)을 의미합니다.
-
corr_matrix = housing.corr()
corr_matrix ["median_house_value"]. sort_values(ascending=False)scikit-learn에서는 corr()란 메서드를 제공하여 두 변수 간의 상관 계수를 측정해줍니다.
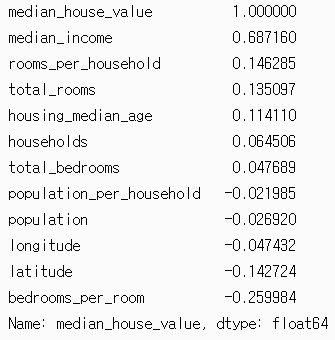
0에 가까운 상관관계를 보여주는 항목들은 해당 항목과 선형적인 상관관계가 없다는 것을 알 수 있고, median_income 같은 변수는 데이터 내의 변수 중에 median_house_value와 가장 강한 양의 상관관계, bedrooms_per_room 같은 변수는 가장 강한 음의 상관관계를 의미합니다. (위의 상관 관계를 시각화하는 메서드는 scatter_matrix()입니다.)
다음 포스팅에서는 이어서 데이터 전처리, 모델 학습, 모델 최적화에 관한 포스팅을 작성할 예정입니다.
머신러닝 입문 관련 데이터세트 프로젝트는 아래의 github 레포지토리에 있습니다.
https://github.com/harim4422/Scikit-Learn-Example
harim4422/Scikit-Learn-Example
Analyze and predict various data to learn how to use Scikit-learn - harim4422/Scikit-Learn-Example
github.com
반응형
'IT > Machine Learning' 카테고리의 다른 글
| 머신러닝 (4) - ML 모델 생성과 훈련, 예측, 평가 (2) | 2020.01.28 |
|---|---|
| 머신러닝 (3) - 데이터 전처리 (0) | 2020.01.22 |
| 추천 시스템 (2) - 실제 시스템 분석 (3) | 2020.01.14 |
| 추천 시스템 (1) - 개요 및 알고리즘 (2) | 2020.01.08 |
| 머신러닝 (1) - 머신러닝을 사용하는 이유와 분류 그리고 문제점 (0) | 2020.01.05 |




