고정 헤더 영역
상세 컨텐츠
본문

Writer: Harim Kang
해당 포스팅은 Tensorflow 2.0, Keras, sklearn을 이용한 딥러닝 분류 네트워크에 대한 내용입니다. 해당 내용은 이항 분류와 다항 분류를 포함하고 있습니다.
딥러닝 네트워크를 이용한 분류
분류(Classification)는 회귀(Regression)와 함께 가장 기초적인 분석 방법입니다. 데이터가 어느 범주(Category)에 속하는지를 판단하는 방법입니다.
이항 분류(Binary Classification)
- 2개의 Label을 갖는 데이터가 들어왔을 때, 0 또는 1로 분류를 하는 것을 의미합니다.
- 활성화 함수는 주로 Sigmoid 함수를 사용합니다. Sigmoid 함수가 0 또는 1로 출력을 하기 때문입니다.
- Sigmoid 대신 Softmax를 사용하는 것이 가능합니다.
이항 분류 예제
-
Dataset
-
독버섯과 일반 버섯의 데이터세트입니다.
-
class라는 항목을 통하여 독버섯 여부가 결정되며, 독 버섯이면 p, 일반 버섯이면 e로 분류가 되어있는 데이터세트입니다.
import pandas as pd mushrooms = pd.read\_csv('mushrooms.csv') mushrooms.head()아래와 같이 class와 그외 특징들까지 총 23개의 특징을 가진 데이터입니다.

-
Label Encoding
from sklearn.preprocessing import LabelEncoder labelencoder=LabelEncoder() for col in mushrooms.columns: mushrooms[col] = labelencoder.fit_transform(mushrooms[col]) mushrooms.head()sklearn에서 제공하는 LabelEncoder클래스를 사용하여 데이터를 정수로 변경시켜보겠습니다. 아래와 같은 결과를 얻을 수 있습니다.

-
Data Preprocessing
y = mushrooms['class'].values x = mushrooms.drop(['class'], axis=1) x = x.values x = (x - x.min()) / (x.max() - x.min()) plt.hist(y) plt.xticks([0, 1]) plt.show()x와 y를 분리하는 작업과 x를 정규화 시키는 작업입니다. y는 class 항목을 따로 모아두었고, x는 학습이 잘 되도록 0과 1사이의 숫자로 정규화를 시켰습니다. class 항목의 분포를 살펴보면 아래와 같습니다.

비슷한 분포를 가지고 있습니다. 이때 0은 독이 없는 일반 버섯을 의미하며, 1은 독이 있는 버섯입니다.
-
Train & Test Dataset Split
from sklearn.model_selection import train_test_split import numpy as np x_train , x_test , y_train , y_test = train_test_split(x, y,test_size=0.2,random_state=42) y_train = tf.keras.utils.to_categorical(y_train, num_classes=2) y_test = tf.keras.utils.to_categorical(y_test, num_classes=2)sklearn의 train_test_split이라는 훈련 데이터세트와 테스트 데이터세트를 분리하여 리턴해주는 클래스를 이용합니다. tf.keras.utils의 to_categorical은 0 또는 1로 이루어진 라벨들을 one-hot encoding시켜서 0은 [1. 0.]으로, 1은 [0. 1.]으로 변환시켜줍니다.

-
Model 형성
model = tf.keras.Sequential([ tf.keras.layers.Dense(units=48, activation='relu', input_shape=(22,)), tf.keras.layers.Dense(units=24, activation='relu'), tf.keras.layers.Dense(units=12, activation='relu'), tf.keras.layers.Dense(units=2, activation='sigmoid') ]) model.compile(optimizer=tf.keras.optimizers.Adam(lr=0.07), loss='binary_crossentropy', metrics=['accuracy']) model.summary()위와 같이 4개의 Dense Layer로 형성된 Sequential 네트워크를 선언하였고, 마지막 Dense Layer에서 units=2로 선언하여 one-hot encoding 형태로 나오도록 설정하였습니다. 또한 활성화 함수를 sigmoid 함수로 선언해주었습니다. 이항분류의 loss function은 binary_crossentropy로 선언하고 성능 평가는 정확도(accuracy)로 측정하도록 하였습니다.
-
Model 훈련
history = model.fit(x_train, y_train, epochs=25, batch_size=32, validation_split=0.25, callbacks=[tf.keras.callbacks.EarlyStopping(patience=3, monitor='val_loss')])다른 신경망 네트워크들과 비슷하게 훈련은 fit메소드를 통해 실행하며, EarlyStopping이라는 callback 함수를 사용하여 val_loss가 3번 이상 연속으로 증가한다면 멈추고 최저의 loss를 사용하도록 선언하였습니다.
-
결과

-
loss와 val_loss모두 낮아지는 이상적인 그래프를 형성 합니다.
-
test세트를 사용한 성능 평가 결과는 아래와 같습니다.

손설 0.03, 정확도 99.3%의 우수한 모델임을 확인할 수 있습니다.
-
-
예측
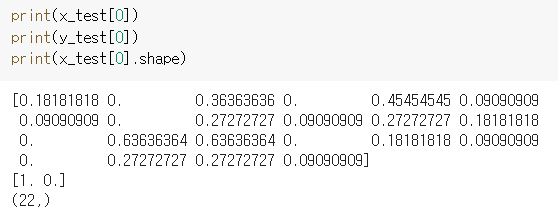
-
test세트의 첫번째 데이터를 사용하여 예측을 해보겠습니다. 해당 데이터는 [1. 0.]으로 라벨이 나온걸로 보아 독이 없는 일반적인 버섯입니다.
-
아래의 결과를 보면 예측 값이 [1. 0.]에 가까운 결과가 나왔습니다.
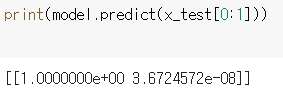
-
실습 코드는 아래의 주소에 있습니다.
https://github.com/harimkang/tensorflow2_deeplearning/blob/master/binary_classification.ipynb
harimkang/tensorflow2_deeplearning
tensorflow2, deep learning study example codes. Contribute to harimkang/tensorflow2_deeplearning development by creating an account on GitHub.
github.com
다항 분류(Multi Classification)
-
3개 이상의 Label을 갖는 데이터에 대한 분류 작업을 의미합니다.
-
딥러닝 네트워크에서 활성화 함수는 주로 Softmax를 사용합니다.
-
Softmax
-
Softmax는 각각 Label별로 확률을 출력하는 활성화 함수입니다.
-
모든 출력 값을 합치면 1이 됩니다.

-
cost function은 cross-entropy를 사용합니다. 그 이유는 미분의 편의성이 있기 때문입니다.
-
출력 값들을 e의 지수로 사용하여 계산 후 모두 더한 값으로 나눈 것들이 결과입니다.
-
max와 비슷한 의미로서, 큰 값을 강조하는 함수이지만, 모든 값의 합이 1이 되도록 유지합니다.
-
큰 값을 강조하고, 작은 값은 약화시키는 효과를 가지고 옵니다.
-
-
마지막 레이어는 softmax 함수를 사용하며, 뉴런의 개수는 class의 개수와 동일하게 정해줍니다. ont-hot encoding을 사용하기 때문에, 출력값이 class 개수와 동일하여야 합니다.
-
categorical_crossentropy
-
다중 분류에서 사용하는 손실 함수입니다. 엔트로피(entropy)는 데이터를 숫자로 정량화하는 단위입니다.
-
엔트로피는 확률의 역수에 로그를 취한 값입니다. 확률이 높을 수록 데이터의 중요도가 낮다고 판단하기 때문에 역수를 취합니다.
-
크로스 엔트로피(crossentropy)는 각 엔트로피에 확률을 곱해준 기댓값과 유사합니다. 확률 대신 네트워크가 예측한 확률값을 곱합니다. 네트워크가 예측한 값을 q(x)라고 합니다.
-
이항은 두개부터, 다항은 세개 이상의 범주로 이루어져있습니다. 범주형 크로스 엔트로피(categorical cross entropy, CCE)는 모든 범주에 대한 크로스 엔트로피의 평균을 내는 것을 의미합니다.
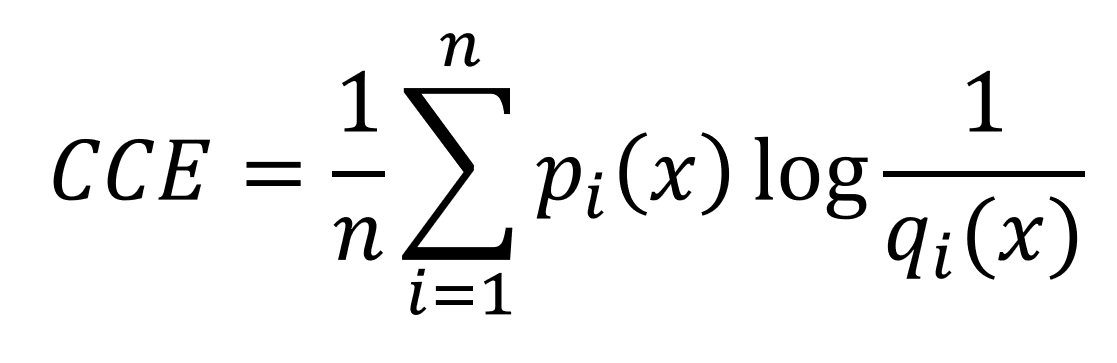
-
네트워크가 아래의 q(x)와 같이 예측을 하였고, 실제 답은 p(x)일 때, CCE는 아래와 같이 구할 수 있습니다.

-
다항 분류 in Tensorflow 2.0
model = tf.keras.Sequential([
tf.keras.layers.Dense(units=48, activation='relu', input_shape=x_train[0].shape),
tf.keras.layers.Dense(units=24, activation='relu'),
tf.keras.layers.Dense(units=12, activation='relu'),
tf.keras.layers.Dense(units=3, activation='softmax')
])
model.compile(optimizer=tf.keras.optimizers.Adam(lr=0.07),
loss='categorical_crossentropy', metrics=['accuracy'])
model.summary()- 클래스가 3개로 나누어진 경우의 모델입니다. 마지막 Dense 레이어의 유닛수가 클래스 수에 맞게 3으로 설정하였습니다.
- softmax 활성화 함수를 사용하였고, 손실함수 categorical_crossentropy를 지정해주고, metric은 정확도를 사용하면 됩니다.
반응형
'IT > Deep Learning' 카테고리의 다른 글
| 딥러닝 (7) - RNN(Recurrent Neural Network), LSTM, GRU (11) | 2020.02.24 |
|---|---|
| 딥러닝 (6) - CNN (Convolutional Neural Network) (2) | 2020.02.24 |
| 딥러닝 (4) - 회귀(Regression) 네트워크 만들기 (0) | 2020.02.12 |
| 딥러닝 (3) - AND, OR, XOR 연산 신경망 만들기 (0) | 2020.02.07 |
| 딥러닝 (2) - 텐서플로우 2.0 기초와 뉴런 만들기 (2) | 2020.02.06 |




