고정 헤더 영역
상세 컨텐츠
본문

Writer: Harim Kang
해당 포스팅은 '시작하세요! 텐서플로 2.0 프로그래밍'책의 흐름을 따라가면서, 책 이외에 검색 및 다양한 자료들을 통해 공부하면서 정리한 내용의 포스팅입니다. 해당 내용은 CNN에 대한 내용을 담고 있습니다. 사용 라이브러리는 Tensorflow 2.0 with keras입니다.
컨볼루션 신경망(Convolutional Neural Network)
CNN(Convolutional Neural Network)은 주로 이미지를 사용한 딥러닝 네트워크 방식에서 사용됩니다. 사실, 이미지 외에 음성과 텍스트, 시간 데이터에도 사용 가능합니다.
CNN의 구성
분류를 위한 컨볼루션 신경망은 특징 추출을 하는 부분과 분류기 부분으로 나누어집니다.

- 특징 추출(Feature Extraction)
- 컨볼루션 레이어(Convolution Layer) + 풀링 레이어(Pooling Layer)를 반복하여 구성
- CNN의 주요한 성질 중 하나는 특징표현 학습(Feature Representation Learning)입니다. 특징 추출 기법인 컨볼루션(Convolution, 합성곱) 연산을 사용하여 이미지의 픽셀을 주변의 픽셀의 조합으로 대체하는 방식입니다.
- 분류기(Classifier)
- Dense Layer + Dropout Layer(과적합을 막기 위한 레이어) + Dense Layer(마지막 Dense 레이어 후에는 Dropout하지 않습니다.)
- 앞선 포스팅에서 설명한 Classification과 같습니다.
컨볼루션 레이어(Convolution Layer)
합성곱(Convolution)

- 합성곱이란 하나의 함수와 또 다른 함수를 반전 이동한 값을 곱하고, 구간에 대해 적분하여 새로운 함수를 구하는 연산자입니다.
- 이미지를 기준으로 설명하자면, 이미지들의 특징 맵(Feature Map)을 찾는 것을 의미합니다.
- 합성곱 연산의 특징은 완전연결 네트워크와는 다르게 데이터의 형상을 유지한다는 점에 있습니다. 그래서 이미지와 같은 형상이 존재하는 데이터에 적합한 연산입니다.
- 합성곱은 특정 크기를 가진 필터(Filter, Kernel)를 일정 간격(Stride)으로 이동하면서 입력 데이터에 연산을 적용합니다.
필터(Filter)
- 어떠한 필터(Filter)를 사용하느냐에 따라 찾을 수 있는 이미지의 특징이 달라집니다.
- 앞선 포스팅들에서 찾고자하는 목표인 가중치라고 생각하시면 될 것 같습니다.
- 딥러닝 기반의 합성곱 연산은 네트워크가 이미지의 특징을 추출하는 필터를 생성합니다. 필터의 가중치를 찾는다고 생각하시면 됩니다.
- 학습을 통해서 점차 특징을 잘 찾는 필터가 생성되도록 합니다.
- 필터 당 하나의 feature map이 형성됩니다. 컨볼루션 레이어에서는 생성된 피쳐 맵을 스택처럼 쌓아둡니다.

이미지 연산

- 이미지는 기본적으로 세개의 채널(Channel)로 이루어져 있습니다. 색이 있기 때문에 RGB로 이루어져 있습니다.
- 컨볼루션 레이어는 각 채널에 대해 계산을 하여 특징 맵을 추출 합니다.
- 일반적인 컨볼루션 신경망은 여러 개의 컨볼루션 레이어를 쌓으면서
Convolution Layer in Tensor flow 2.0
conv = tf.keras.layers.Conv2D(kernel_size=(3, 3), strides=(2, 2), padding='valid', filters=16)-
tf.keras.layers.Conv2D
-
2차원 이미지를 다루는 컨볼루션 레이어 클래스입니다.
-
kernel_size: 필터 행렬의 크기를 결정합니다.
-
strides: 필터가 계산 과정에서 한 스텝마다 이동하는 크기를 의미합니다. 크기에 따라

-
padding: 연산 전에 주변에 빈 값을 넣어서 이미지의 크기를 유지할 것인지에 대한 설정을 합니다. 'valid' 값은 비활성화, 'same'값은 빈 값을 넣어서 입력과 출력의 크기가 같도록 합니다. 빈 값이 0인 경우에 zero padding이라고 합니다.

-
filters: 필터의 개수입니다. 많을수록 많은 특징을 추출할 수 있지만, 학습 속도가 느리고 과적 합의 문제가 발생할 수 있습니다. VGG의 경우에는 네트워크 깊이에 따라 필터를 2배씩 늘려갑니다.
-
풀링 레이어(Pooling Layer)
풀링 레이어는 인접 픽셀들 중에서 중요한 정보만을 남기기 위해서 서브 샘플링(subsampling) 기법을 사용합니다. 이것은 이미지를 구성하는 픽셀들이 인접한 픽셀들끼리는 비슷한 정보를 가진다는 특성에 기반합니다. 이를 통해 과적합을 방지하고, 효율적인 계산을 하게 만들어줍니다. 해당 레이어는 가중치가 존재하지 않아서 학습되지 않는 레이어입니다.
Pooling Layer in Tensor flow 2.0
-
tf.keras.layers.MaxPool2D(): 최대 풀링 레이어
-
컨볼루션 레이어에서 더 많이 사용되는 레이어입니다.
-
사소한 픽셀의 값을 무시하고, 가장 큰 특징을 나타내는 값을 기록하는 방식입니다.
pool = tf.keras.layers.MaxPool2D(pool\_size=(2, 2), strides=(2, 2)) -
pool_size: 연산 범위를 의미합니다. 해당 범위 내의 가장 큰 수만을 가져옵니다.
-
strides: Conv2D레이어에서의 역할과 동일합니다.

-
-
tf.keras.layers.AveragePooling2D: 평균 풀링 레이어
-
최대 풀링 레이어와 다른 점은 최대 값이 아닌 평균값을 사용한다는 점입니다.
-
전체적인 평균 값을 사용하므로, 해당 이미지의 경향을 살린 채로 진행된다는 의미입니다.

-
플래튼 레이어(Flatten Layer)
CNN에서 컨볼루션 레이어와 풀링 레이어를 반복적으로 거치면 주요 특징만 추출됩니다. 추출된 주요 특징은 2차원 데이터로 이루어져 있지만, Dense와 같이 분류를 위한 학습 레이어에서는 1차원 데이터로 바꾸어서 학습이 되어야 합니다.
Flatten in Tensor flow 2.0
tf.keras.layers.Flatten()2차원 데이터를 1차원 데이터로 바꾸는 역할의 레이어입니다.
드롭아웃 레이어(Dropout Layer)
네트워크가 과적합되는 경우를 방지하기 위해서 만들어진 레이어입니다. 이것은 학습 과정에서 무작위로 뉴런의 집합을 제거하는 것이 과적합을 막는다는 아이디어에서 나왔습니다.
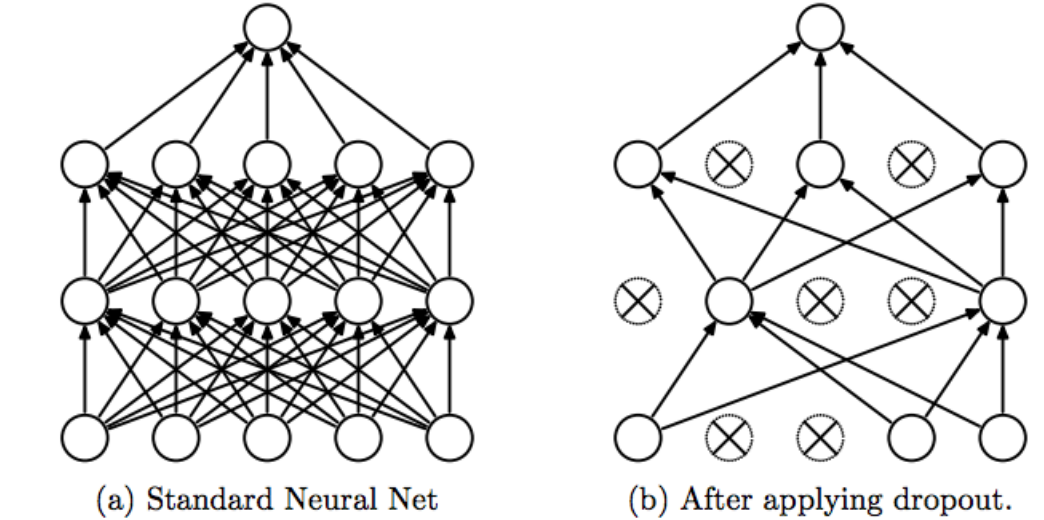
위의 그림처럼 무작위로 부분적인 뉴런을 제거하는 방식입니다. 기존의 방식은 각각의 레이어에 존재하는 뉴런들은 같은 결괏값을 받아서 해당 결괏값의 영향이 지속됩니다. 학습 시에는 일부 뉴런을 제거하여 이러한 영향력을 줄여서 학습시키고, 테스트에서는 모든 값을 포함하여 계산하는 방법입니다.
Dropout in Tensor flow 2.0
-
tf.keras.layers.Dropout()
do = tf.keras.layers.Dropout(rate=0.2)- rate: 제외할 뉴런의 비율을 나타내는 값입니다.
- 이러한 드롭아웃 레이어는 모든 주요 컨볼루션 신경망에 사용되고 있습니다.
- 해당 레이어도, 가중치가 존재하지 않아서 학습이 되지 않습니다.
- 과적합 방지를 위한 역할입니다.
전체적인 CNN 모델 생성
model = tf.keras.Sequential([
tf.keras.layers.Conv2D(input_shape=(28, 28, 1), kernel_size=(3, 3), filters=16),
tf.keras.layers.MaxPool2D(strides=(2, 2)),
tf.keras.layers.Conv2D(kernel_size=(3, 3), filters=32),
tf.keras.layers.MaxPool2D(strides=(2, 2)),
tf.keras.layers.Conv2D(kernel_size=(3, 3), filters=64),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(units=128, activation='relu'),
tf.keras.layers.Dropout(rate=0.3),
tf.keras.layers.Dense(units=10, activation='softmax')
])위와 같은 코드와 같이 Sequential 한 CNN 모델을 만들 수 있습니다. CNN의 구성에서 설명한 그림과 동일한 순서의 모델을 구성할 수 있습니다.
또는 아래의 코드로도 모델을 생성할 수 있습니다.
model = tf.keras.Sequential()
model.add(tf.keras.layers.Conv2D(input_shape=(28, 28, 1), kernel_size=(3, 3), filters=16))
model.add(tf.keras.layers.MaxPool2D(strides=(2, 2)))
model.add(tf.keras.layers.Conv2D(kernel_size=(3, 3), filters=32))
model.add(tf.keras.layers.MaxPool2D(strides=(2, 2)))
model.add(tf.keras.layers.Conv2D(kernel_size=(3, 3), filters=64))
model.add(tf.keras.layers.Flatten())
model.add(tf.keras.layers.Dense(units=128, activation='relu'))
model.add(tf.keras.layers.Dropout(rate=0.3))
model.add(tf.keras.layers.Dense(units=10, activation='softmax'))두 코드 모두 같은 동작이니 쓰시면 될 것 같습니다.

모델의 요약을 보자면 위와 같은 설명을 얻을 수 있습니다.
CNN 모델의 성능 향상
CNN 모델의 성능을 더 끌어올리는 방법은 어떤 것이 있을까요? 대표적으로 두 가지를 생각할 수 있습니다.
-
레이어를 더 쌓는 방법
-
딥러닝이 발전할수록 컨볼루션 레이어가 중첩된 더 깊은 구조가 나타납니다.
-
AlexNet(2012, 8 Layers), VGGNet(2014, 19 Layers), GoogLeNet(2014, 22 Layers), ResNet(2015, 152 Layers)
-
VGGNet스타일의 14 Layers 네트워크 모델
model = tf.keras.Sequential() model.add(tf.keras.layers.Conv2D(input_shape=(28, 28, 1), kernel_size=(3, 3), filters=32, padding='same', activation='relu')) model.add(tf.keras.layers.Conv2D(kernel_size=(3, 3), filters=64, padding='same', activation='relu')) model.add(tf.keras.layers.MaxPool2D(pool_size=(2, 2))) model.add(tf.keras.layers.Dropout(rate=0.5)) model.add(tf.keras.layers.Conv2D(kernel_size=(3, 3), filters=128, padding='same', activation='relu')) model.add(tf.keras.layers.Conv2D(kernel_size=(3, 3), filters=256, padding='valid', activation='relu')) model.add(tf.keras.layers.MaxPool2D(pool_size=(2, 2))) model.add(tf.keras.layers.Dropout(rate=0.5)) model.add(tf.keras.layers.Flatten()) model.add(tf.keras.layers.Dense(units=512, activation='relu')) model.add(tf.keras.layers.Dropout(rate=0.5)) model.add(tf.keras.layers.Dense(units=256, activation='relu')) model.add(tf.keras.layers.Dropout(rate=0.5)) model.add(tf.keras.layers.Dense(units=10, activation='softmax'))위의 구조를 요약하면 아래와 같습니다.

학습 시, Tensorboard를 통해서 아래와 같은 네트워크 그래프를 얻을 수 있습니다.
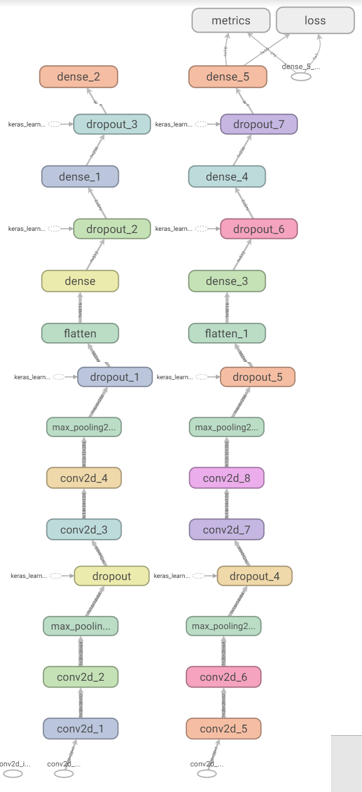
위와 같이 레이어를 더 깊게 쌓으면 더 좋은 성능을 기대할 수 있습니다.
-
-
이미지 보강 법(Image Augmentation)
-
해당 방식은 훈련 데이터를 보강하는 방식입니다.
-
기존의 훈련 데이터가 있을 때, 해당 데이터를 원본으로, 여러 변형을 시켜서 해당 데이터를 학습 데이터에 포함시키는 방법입니다.
-
뒤집거나(horizontal flip), 회전(rotate), 기울임(shear), 확대(zoom), 평행이동(shift) 등의 방식으로 원본을 여러 개의 데이터로 만들어냅니다.
-
tf.keras.preprocessing.image.ImageDataGenerator()
from tensorflow.keras.preprocessing.image import ImageDataGenerator import numpy as np img_generator = ImageDataGenerator( rotation_range=10, room_range=0.10, shear_range=0.5, width_shift_range=0.10, height_shift_range=0.10, horizontal_flip=True, vertical_flip=False) augment_size = 100 x_augmented = img_generator.flow( np.tile(train_X[0].reshape(28*28), 100).reshape(-1, 28, 28, 1), np.zeros(augment_size), batch_size=augment_size, shuffle=False).next()[0]- rotation_range: 생성하고자 하는 이미지 회전 반경을 설정합니다.
- zoom_range: 생성하고자 하는 이미지 확대 범위를 설정합니다.
- shear_range: 기울기 정도를 설정합니다.
- ImageDataGenerator.flow(): 실제로 보강된, 실제로 만들어진 이미지를 생성하는 함수입니다. Iterator로 반환되어, 순차적으로 next() 함수를 사용하여 꺼내서 쓰면 됩니다.
- 한 번에 꺼내는 데이터의 수를 조절하기 위해서 batch_size를 설정할 수 있습니다.
-
CNN 실습
Fashion_MNIST 코드 : https://github.com/harimkang/tensorflow2_deeplearning/blob/master/CNN_fashion_MNIST.ipynb
Kaggle The Simpsons Characters Data : https://www.kaggle.com/alexattia/the-simpsons-characters-dataset
심슨 데이터세트 실습 코드: https://github.com/harimkang/tensorflow2_deeplearning/blob/master/cnn_kaggle.ipynb
harimkang/tensorflow2_deeplearning
tensorflow2, deep learning study example codes. Contribute to harimkang/tensorflow2_deeplearning development by creating an account on GitHub.
github.com
Reference
Convolution: http://wiki.hash.kr/index.php/합성곱_신경망
pooling: https://keras.io/layers/pooling/
dropout layer: https://towardsdatascience.com/machine-learning-part-20-dropout-keras-layers-explained-8c9f6dc 4c9ab
반응형
'IT > Deep Learning' 카테고리의 다른 글
| 딥러닝 (8) - [RL1] 강화학습(Reinforcement Learning)이란? (0) | 2020.03.22 |
|---|---|
| 딥러닝 (7) - RNN(Recurrent Neural Network), LSTM, GRU (11) | 2020.02.24 |
| 딥러닝 (5) - 분류(Classification) 네트워크 (1) | 2020.02.24 |
| 딥러닝 (4) - 회귀(Regression) 네트워크 만들기 (0) | 2020.02.12 |
| 딥러닝 (3) - AND, OR, XOR 연산 신경망 만들기 (0) | 2020.02.07 |




