고정 헤더 영역

상세 컨텐츠
본문
첫 번째 글에서는 AI 에이전트가 무엇인지, 그리고 제대로 작동하는 에이전트를 만들기 위해 AgentOps라는 운영 전략이 얼마나 중요한지 알아보았습니다. AgentOps의 핵심에는 '측정하고 최적화한다'는 원리가 있다고 말씀드렸습니다.
Agents Companion (1): 기본 아키텍처와 필수 운영 전략, AgentOps
Agents Companion (1): 기본 아키텍처와 필수 운영 전략, AgentOps
최근 구글은 'Agents Companion' 이라는 제목의 Whitepaper를 게시하고 공유했습니다. 해당 자료는 생성형 AI 에이전트의 진화하는 기술과 실제 적용 사례에 대해 다루고 있습니다. 특히 멀티 에이전트
davinci-ai.tistory.com
이번 글에서는 바로 그 '측정하고 최적화한다'는 원리를 구현하기 위한 핵심 과정, 즉 AI 에이전트의 실력을 제대로 평가하는 방법에 대해서 정리해보겠습니다.
AI 에이전트 평가: 똑똑한 비서의 실력 검증 📝
아이디어 단계의 AI 에이전트를 실제 서비스에 적용하려면, 에이전트가 의도한 대로, 그리고 신뢰할 수 있게 작동하는지를 철저히 확인해야 합니다. 단순히 최종 결과만 보는 것이 아니라, 에이전트가 왜 그런 행동을 했는지, 어떤 단계를 거쳤는지를 깊이 이해하는 것이 중요합니다. 에이전트 평가는 크게 세 가지 주요 부분으로 나눌 수 있습니다:
1. 에이전트 능력 평가 (Assessing Agent Capabilities)
이는 에이전트의 기본적인 역량을 검증하는 과정입니다. 지시 이해, 논리적 추론, 도구 사용 능력 등을 평가합니다.
에이전트의 특정 사용 사례를 평가하기 전에, 공개적으로 사용 가능한 벤치마크와 기술 보고서를 통해 에이전트 구축 시 고려해야 할 핵심 역량 및 한계에 대한 통찰력을 얻을 수 있습니다. 모델 성능, 환각(hallucinations), 도구 호출(tool calling) 및 계획(planning)과 같은 근본적인 에이전트 기능에 대한 공개 벤치마크가 존재합니다.
Ex. Berkeley Function-Calling Leaderboard (BFCL)와 τ-bench: 도구 선택 및 사용 능력을 평가
예를 들어 아래 그림과 같은 구조의 AgentBench 같은 전체론적 에이전트 벤치마크가 있으며 여러 시나리오에 걸친 종단 간(end-to-end) 성능을 포착하려 시도합니다. 하지만 특정 사용 사례에 적합한지 평가하려면 별도 평가가 필요합니다. 따라서 다양한 시나리오에서의 행동 평가가 중요합니다. (Ex. 특정 사용 사례에 특화된 공개 벤치마크: Adyen의 DABStep)
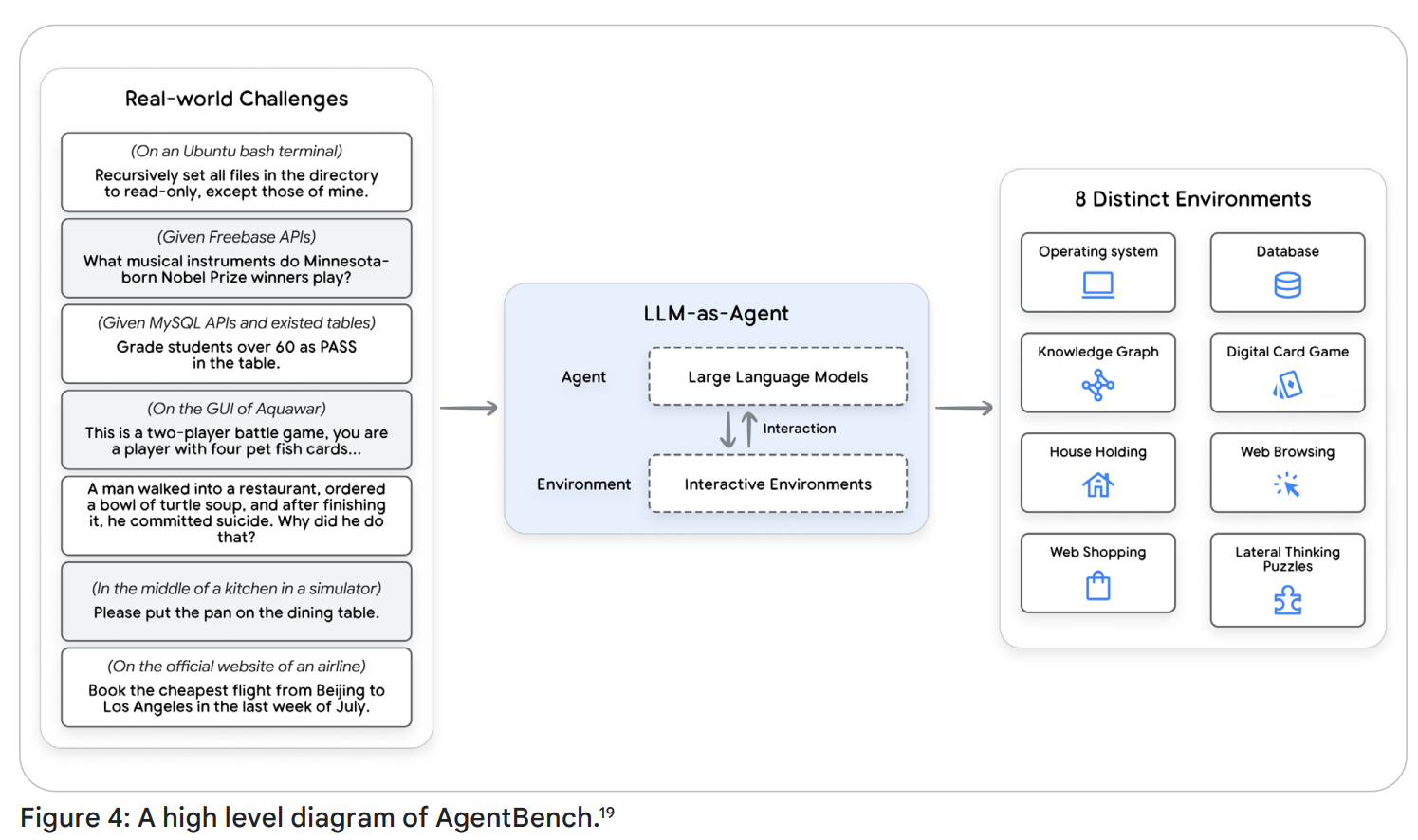
2. 움직임(궤적) 및 도구 사용 평가 (Evaluating Trajectory and Tool Use)
에이전트가 목표를 달성하기 위해 수행하는 일련의 행동 순서를 ‘궤적(Trajectory)’이라고 합니다. 이 궤적을 평가하면 에이전트의 작동 방식을 이해하고, 오류나 비효율을 개선할 수 있습니다. 마치 블랙박스처럼 작동 과정을 추적(trace)하는 것입니다.
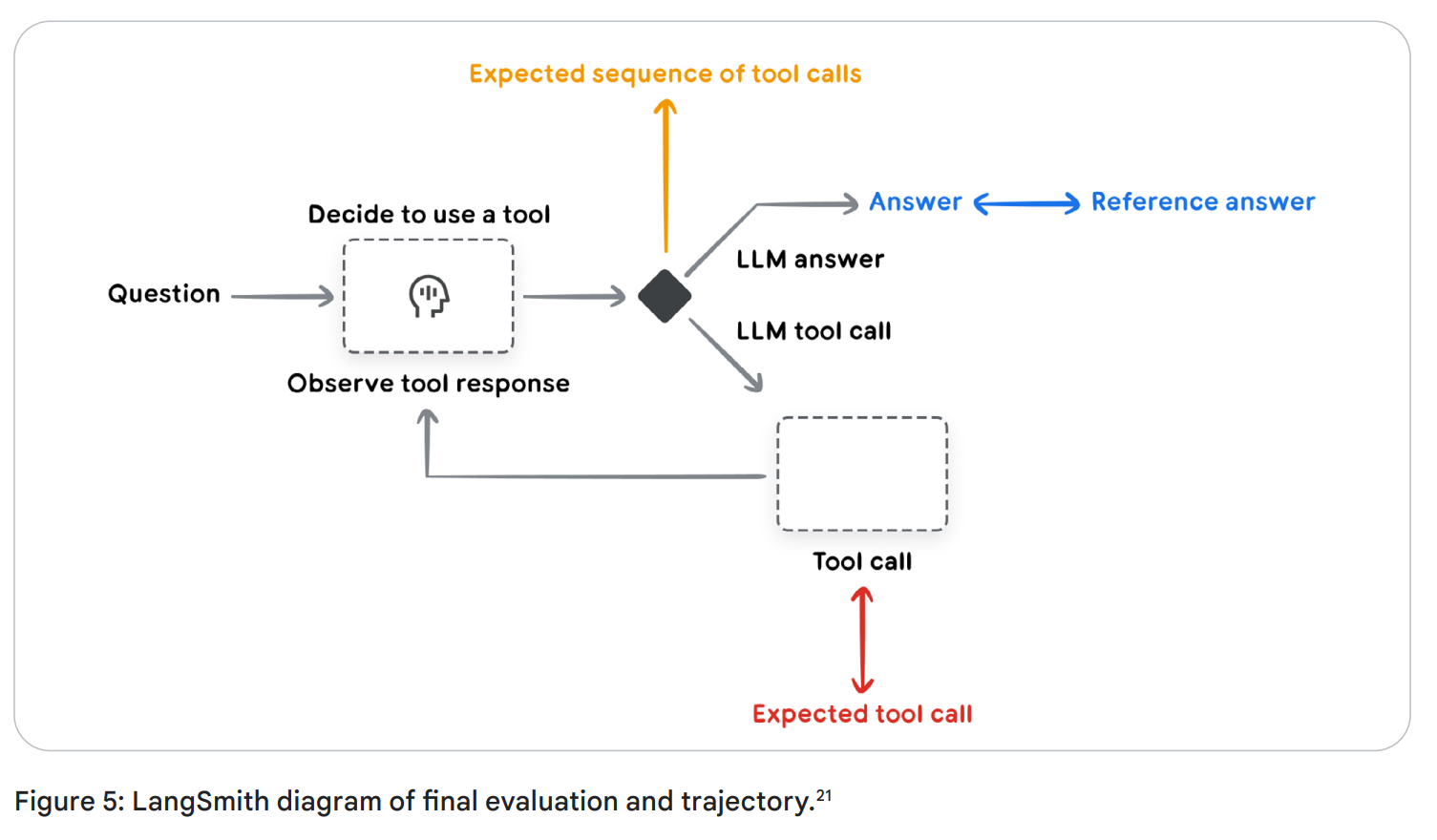
(해당 문서의 예제 도구로는 LangSmith가 사용되고 있습니다. LangSmith 사용법은 추후 시간이 된다면 작성해보겠습니다.)
자동화된 궤적 평가 기준은 다음과 같습니다:
- 완벽 일치 (Exact match): 이상적인 궤적과 완전히 일치해야 성공 - 가장 엄격한 지표
- 순서 일치 (In-order match): 핵심 단계의 순서를 평가 - 불필요 또는 추가 행동을 허용
- 순서 무관 일치 (Any-order match): 단계 포함 여부만 평가, 순서는 고려하지 않음 - 모든 행동을 했는지만 검사
- 정밀도 (Precision): 사용한 도구 중 실제 필요한 비율
- 재현율 (Recall): 필요한 도구 중 실제 사용된 비율
- 단일 도구 사용 (Single-tool use): 특정 도구 사용 여부 평가 - 에이전트가 특정 도구를 사용하는 방법을 학습했는지 파악하는 데 도움
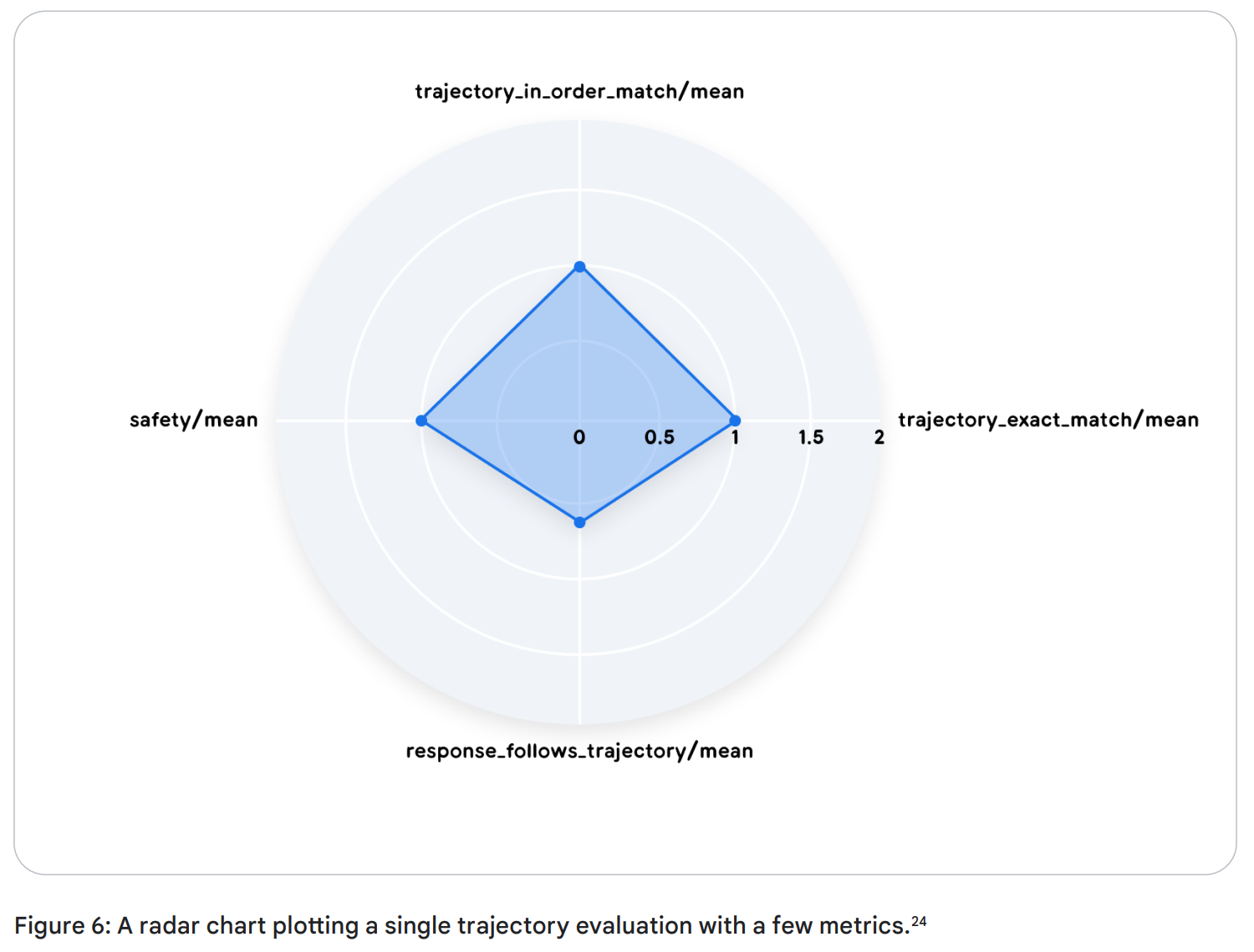
이러한 평가는 ‘이상적인 참조 궤적(Ground truth)’이 필요하며, 이를 위해 평가용 데이터셋 구축이 필수입니다. (이것은 자원이 소모되는 방식이므로, Agent as a Judge 같은 에이전트 자동 평가자 autoraters 와 같은 연구가 진행 중입니다)
3. 최종 응답 평가 (Evaluating the Final Response)
에이전트가 사용자에게 제공하는 최종 결과물의 품질을 평가합니다. 핵심은 "에이전트가 목표를 달성했는가?"입니다. 이러한 평가를 위해 특정 요구사항에 맞춰 사용자 정의 성공 기준을 정의할 수 있습니다. 예를 들어, 소매 챗봇이 제품 질문에 정확하게 답변하는지 또는 연구 에이전트가 적절한 어조와 스타일로 연구 결과를 효과적으로 요약하는지 등을 평가할 수 있습니다.
개발자들이 시작할 때 가장 일반적이고, 실용적인 접근 방식 중 두 가지는 2번 궤적 평가와 3번 최종 응답 평가입니다.
앞서 말한 것처럼, 자동화된 평가를 위해 Autorater라는 시스템을 사용할 수 있으며, 이는 다른 LLM이 평가자 역할을 수행합니다. 단, 창의성, 상식, 맥락 이해 등은 자동화가 어려우므로 Human-in-the-Loop(HITL) 방식이 필요합니다. 또한 평가가 무엇을 중점적으로 볼 것인지 명확하게 하기 위해 평가 기준을 매우 정확하게 정의해야 합니다.
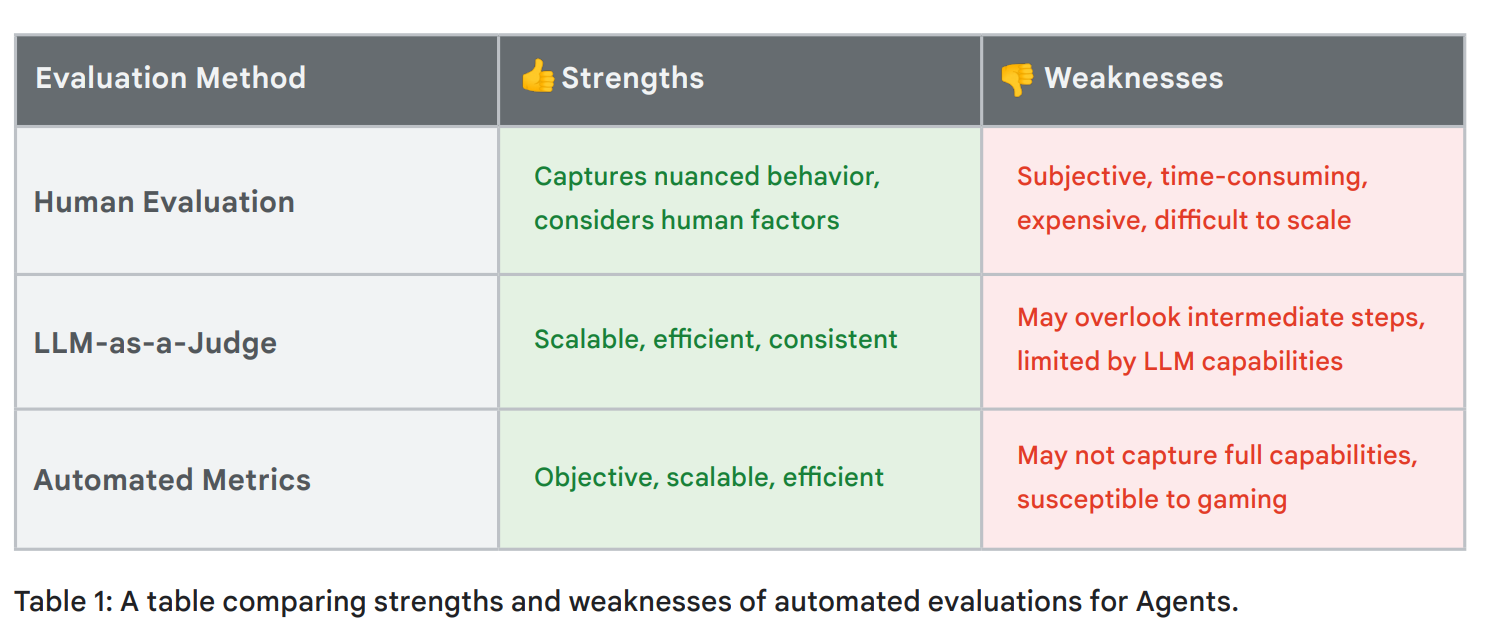
Agent Evaluation은 반드시 필요한 부분이며, 많은 강점도 있지만 여전히 많은 도전 과제를 가지고 있으며, 향후 발전이 기대되는 분야입니다. 주요한 도전 과제는 아래와 같습니다.
- 평가 데이터 확보의 어려움: 에이전트 평가를 위한 적절한 데이터를 찾기 어려울 수 있습니다.
- 평가의 불완전성: 합성 데이터나 심사관 역할을 하는 LLM(LLM-as-a-Judge)을 사용한 평가도 불완전할 수 있습니다.
- LLM-as-a-Judge의 한계: 최종 결과보다는 에이전트의 추론 과정이나 중간 행동을 간과할 수 있습니다.
- 기존 시스템 방법론 계승: 대화 시스템이나 워크플로우 시스템에서 사용된 평가 방법을 에이전트의 능력(예: 여러 상호작용을 통해 작업 성능 개선) 평가에 어떻게 적용할지 더 탐구해야 합니다.
- 멀티모달 평가의 복잡성: 이미지, 오디오, 비디오 등 멀티모달 생성에 대한 평가는 자체적인 방법과 지표가 필요합니다.
- 실제 환경의 예측 불가능성: 동적이고 예측 불가능한 실제 환경에서의 에이전트 평가는 통제된 설정보다 더 어렵습니다.
그렇다면 어떤 노력을 해야하며, 어떻게 발전하고 있을까요?
- 프로세스 기반 평가로 전환: 에이전트의 결과 뿐 아니라 추론 과정을 이해하는 데 중점을 두는 방향으로 나아가야 합니다.
- AI 지원 평가 방법 증가: 확장성 개선을 위해 AI의 도움을 받는 평가 방법이 늘고 있습니다.
- 실제 애플리케이션 문맥에 강한 초점: 실제 사용 사례에서의 평가 중요성이 강조됩니다.
- 새로운 표준화된 벤치마크 개발: 객관적인 에이전트 비교를 위한 벤치마크 개발이 주목받고 있습니다.
- 설명 가능성 및 해석 가능성 강조: 에이전트 행동에 대한 더 깊은 통찰을 제공하기 위해 중요해지고 있습니다.
이번 편에서는 생성형 AI 에이전트의 다양한 평가 방식과 도전과제들을 알아봤습니다. 다음 내용은 "Multiple-Agents" 파트입니다. 다중 에이전트 시스템과 그것의 평가 방식에 대해서 알아보겠습니다.
Agents Companion (3): 다중 에이전트 시스템과 평가 (Multiple Agents & Their Evaluation)
Agents Companion (3): 다중 에이전트 시스템과 평가 (Multiple Agents & Their Evaluation)
이전 글에서는 AI 에이전트의 기본적인 아키텍처와 프로덕션 단계로 나아가기 위한 AgentOps 운영 전략의 중요성, 그리고 에이전트 운영의 핵심 원리인 '측정하고 최적화한다'는 원리를 구현하기
davinci-ai.tistory.com
(해당 글은 구글의 Agents Companion White Paper 내용을 정리한 문서이며, 일부 필요에 따라 내용을 재배치하였습니다.)
반응형
'IT > Agentic AI' 카테고리의 다른 글
| Agents Companion (6): 에이전트의 제품화? 에이전트에서 계약자로, From agents to contractors (1) | 2025.05.08 |
|---|---|
| Agents Companion (5): 기업을 위한 에이전트?, Agents in the enterprise (3) | 2025.05.08 |
| Agents Companion (4): Agentic RAG: RAG의 결정적 진화 (1) | 2025.05.08 |
| Agents Companion (3): 다중 에이전트 시스템과 평가 (Multiple Agents & Their Evaluation) (0) | 2025.05.07 |
| Agents Companion (1): 기본 아키텍처와 필수 운영 전략, AgentOps (0) | 2025.05.06 |




