고정 헤더 영역
상세 컨텐츠
본문

Writer: Harim Kang
데이터 수집 및 저장 계획
데이터 수집 및 전환
-
데이터 수집
-
프로세스
- 수집 데이터 도출: 서비스 품질 결정, 전문가 의견 수렴
- 목록 작성: 수집 가능성, 보안, 세부 데이터 항목, 비용 등을 검토하여 데이터 수집 목록 작성
- 데이터 소유기관 파악 및 협의: 소유자의 데이터 관련 정보 파악 및 협의
- 데이터 유형 분류 및 확인
- 수집 기술 선정: 데이터 유형 및 포맷에 맞는 수집 기술 선정, 확장성, 안정성, 실시간성 및 유연성 확보
- 수집 계획서 작성
- 수집 주기 결정: 배치 또는 실시간
- 데이터 수집 실행: 테스트 진행 후 데이터 수집
-
수집 데이터 대상
- 내부 데이터
- 조직 내부 데이터, 담당자와 협의, 수집이 용이한 정형 데이터, 수명 주기 관리 용이
- 외부 데이터
- 조직 외부 데이터, 특정 기관의 담장자 협의 또는 데이터 전문 업체를 통해 수집, 공공 데이터, 수집이 어려운 비정형 데이터가 많다
- 내부 데이터
-
데이터 수집 방식
-
정형 데이터 수집
-
ETL(Extract Transform Load)

- 데이터 분석을 위한 데이터를 DW(Data Warehouse) 또는 DM(Data Mart)로 이동시키기 위해 원본 데이터를 추출(Extract), 변환(Transform), 적재(Load)하는 작업 및 기술
-
FTP(File Transfer Protocol)
- 원격지 시스템간의 파일 공유를 목적으로한 TCP/IP기반 통신 프로토콜
- Active FTP: 클라이언트가 데이터를 수신받을 포트를 서버에 알리고, 서버의 20번 포트를 통해 클라이언트의 임의 포트로 데이터를 전송해 주는 방식 (서버의 21번 포트를 통해 명령을, 데이터는 20번 포트로 전송)
- Passive FTP: 서버가 데이터를 송신할 포트를 클라이언트에게 알려주면 클라이언트가 해당 서버의 포트에서 데이터를 가져가는 방식 (서버의 21번이 명령, 1024번 이후 포트로 데이터 전송)
-
API(Application Programming Interface): 시스템 연동을 통해 실시간으로 데이터를 수신할 수 있는 기능 제공 기술
-
DBToDB: DBMS간 데이터 동기화 및 전송 기술
-
Rsync(Remote Sync): 서버-클라이언트 방식으로 1:1로 파일과 디렉토리를 동기화하는 기술
-
Sqoop
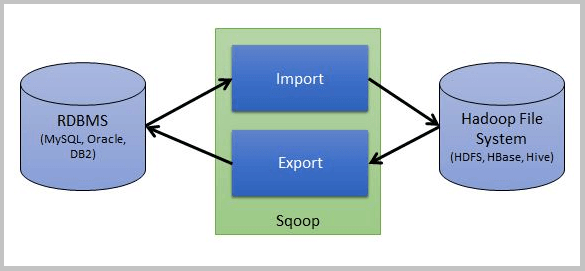
- http://sqoop.apache.org/
- Connector를 사용하여 RDB와 하둡간 데이터 전송을 제공, 모든 적재 과정이 자동화, 병렬 처리
- Bulk Import: 전체 DB또는 Table을 HDFS로 한 번에 전송
- 데이터 전송 병렬화: 시스템 사용률과 성능을 고려한 병렬 전송
- RDB에 Mapping하여 HBase와 Hive에 직접 import 가능
- 자바 클래스 생성을 통한 데이터 interaction
-
-
비정형 데이터 수집
-
Crawling: 웹 사이트에서 문서 및 콘텐츠 수집
-
RSS(Rich Site Summary): XML기반의 배포 프로토콜을 활용하여 수집
-
Open API: 실시간으로 데이터를 수신하도록 공개된 API를 제공하여 데이터 수집
-
Scrapy

- 파이썬 기반의 웹 크롤러
- 단순하고 쉬운 수집을 제공하며, 다양한 부가 기능도 제공
- Spider(스크래핑 범위 명시), Selector(HTML 요소 선택), Items(사용자 정의 자료구조), Pipelines(결과를 아이템 형태로 구성할 때, 가공하거나 파일로 저장 제공), Settings(Spider와 Pipeline 동작을 위한 설정)
-
Apache Kafka

- http://kafka.apache.org/
- 대용량 실시간 로그 처리 분산 스트리밍 플랫폼
- 신뢰성: 메모리 및 파일 큐 기반의 채널 지원
- 확장성: Multi Agent와 consolidation, Fan Out Flow 방식으로 구성 → Scale-Out이 가능, 수집 분산 처리 가능
- Pub-Sub 모델의 메시지 큐
- Broker: 다수의 브로커를 클러스터로 구성, topic이 생성되는 물리적 서버
- Topic: Broker에서 데이터의 발행/소비 처리를 위한 저장소
- Provider: Broker의 특정 topic에 데이터를 전송
- Consumer: Broker의 특정 topic에서 데이터를 수신
- 발행자(Producer)가 메시지를 특정 수신자에게 직접 보내는 방식이 아니라 주제(topic)에 맞게 브로커(Broker)에게 전달하면 구독자(Consumer)가 브로커에 요청해서 가져가는 방식입니다.
-
-
반정형 데이터 수집
-
Sensing
-
Streaming
-
Flume

- http://flume.apache.org/
- Event와 Agent를 활용하여 많은 양의 로그 데이터를 효율적으로 수집, 집계, 이동시키는 기술
- Event: Flume에서 전달하는 데이터 단위, 헤더와 바디로 구성
- Agent: 소스(Source), 채널(Channel), 싱크(Sink)로 구성된 데이터 수집을 위한 JVM 프로세스, 소스로 입력된 메시지를 채널에 저장하고, 저장된 메시지 묶음을 싱크로 전달
-
Scribe
- https://github.com/facebookarchive/scribe
- 페이스북에서 제작한 로그 수집 시스템 (현재는 페이스북에서 사용하지 않는다)
- 다수 서버로부터 실시간의 로그 데이터를 수집하여 분산 시스템에 데이터를 저장하는 대용량 실시간 로그 수집 기술
- 단일 중앙 서버와 다수의 로컬 서버로 구성되어 안정성, 확장성 제공
- 실시간 스트리밍 수집, 확장성, 데이터 수집 다양성, 고가용성
-
Chukwa
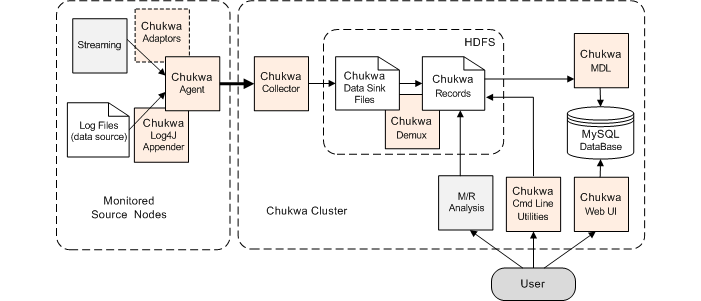
- http://chukwa.apache.org/
- 분산된 각 서버에서 Agent를 실행, Collector가 데이터를 받아서 HDFS에 저장
- Agent: 로그를 수집할 대상 서버에 설치, 해당 서버의 로그나 서버 정보를 Collector로 전송, Fail over 기능과 Check-point 기능을 통해 데이터 유실 방지
- Collector: 여러 대의 Agent로부터 데이터를 받아서 HDFS에 저장
- Data processing: 수신한 데이터에 대해 Archiving(로그에 대해 시간 순서로 동일한 그룹으로 묶는 작업), Demux(로그를 파싱해서, Key-value 쌍으로 구성되는 Chukwa Record를 생성하여 파일로 저장) 등의 작업을 수행해서 처리
- HICC(Hadoop Infrastructure Care Center): 하둡 클러스터의 로그 파일과 시스템 정보를 수집해서 분석한 후, 웹 UI를 통해 보여줌
- HDFS연동, 실시간 분석 제공, Chunk(Metadata 존재) 단위 처리
-
-
-
-
데이터 유형 및 속성 파악
- 데이터 유형은 구조, 시간, 저장 형태에 따라 분류할 수 있다.
- 구조 관점
- 정형 데이터(Structured)-반정형 데이터(Semi-structured)-비정형 데이터(Unstructured)
- 정형: RDB, 스프레드시트 - 반정형: XML, Json
- 시간 관점
- 실시간(Realtime)-비실시간(Non-realtime)
- 저장 형태 관점
- File(로그, 텍스트, 스프레드시트) - DB(Column또는 Table 등에 저장된 데이터) - Content(Text, Image, Media data) - Stream(Sensor Data, HTTP Transaction)
- 데이터 형태에 따른 분류
- 정성적 데이터(Qualitative Data): 언어, 문자 - 저장, 검색, 분석에 많은 비용 소모
- 정량적 데이터(Quantitative Data): 수치, 도형, 기호 - 정령화가 된 데이터, 비용 소모가 적다
- 데이터 속성 분류
- 범주형(Categorical)
- 조사 대상을 특성에 따라 범주로 구분된 변수, 질적 변수, 연산 무의미
- 순서형: 어떤 기준에 따라 순서에 의미 부여가 가능한 경우(상태 양호, 보통, 나쁨)
- 명목형: 명사형으로, 크기와 순서가 없고, 이름만 의미 부여가 가능한 경우(삼성, LG, Apple)
- 수치형(Measure)
- 양적인 수치로 측정되는 변수, 양적 변수, 연산 가능
- 연속형: 구간안의 모든 값을 가질 수 있는 경우(아이들의 키)
- 이산형: 취할 수 있는 값을 셀 수 있는 경우(틀린 문제 개수)
- 측정 척도
- 명목 척도(Nominal Scale): 현역/예비역, 혈액형 구분
- 서열/순위 척도(Ordinal Scale): 맛집 별점
- 등간/간격/거리 척도(Interval Scale): 미세먼지 수치
- 비율 척도(Ratio Scale): 나이, 키, 금액, 거리, 넓이
- 범주형(Categorical)
-
데이터 변환
- 데이터 처리 절차: 수집 → 저장관리 → 분석 → 서비스 제공 및 이용
- 저장 관리: 데이터 전/후 처리 → 저장 → 보안관리 → 품질관리
- 전처리 고려사항
- 유형 분류 시, 분류 기준 적용 기능 제공
- 변환에 필요한 알고리즘 또는 구조를 정의하는 기능 제공
- 사용자 지정 기준에 맞는지 확인
- 실패 시, 재시도 기능 제공 또는 취소 기능 제공
- 실패 이력 저장 및 사용자 전달
- 결과 데이터 저장 기능 제공
- 후처리 고려사항
- 이상값(Outlier)을 변환 또는 추천 기능 제공
- 집계(Aggregation)시 데이터 요약 기능 제공
- 구간 추출 등의 확인 기능 제공 → 변환, 패턴, 이벤트 감시 기능 제공
- 원시 데이터 세트와 변환 후 데이터 세트 간의 변환 로그 저장 기능 제공
- 데이터 처리 단계
- 전처리: 수집 데이터를 저장소에 적재하기 위해 데이터 필터링, 유형 변환, 정제 등의 기술 사용하여 데이터 변환
- 후처리: 저장 데이터를 분석에 용이하도록 변환, 통합, 축소 등의 기술 사용하여 가공
- 변환 기술
- 평활화(Smoothing): 잡음 제거를 위해 이상 값들을 변환 → 분포를 매끄럽게 만든다, 구간화, 군집화
- 집계(Aggregation): 다양한 방식으로 데이터를 요약 → 여러 속성을 단일화, 유사 데이터를 줄이기, 스케일 변경
- 일반화(Generalization): 특정 구간에 분포하는 값으로 스케일을 변환, 범용 데이터에 적합한 모델을 만드는 기법, 이상값과 노이즈에 잘 흔들리지 않는다
- 정규화(Normalization)
- 데이터를 정해진 구간으로 변환 (ex. 0
1, -11) - Min-Max 정규화: 모든 데이터에 대해 최솟값 0, 최댓값 1, 나머지는 0~1 사이의 값으로 변환 → 이상값이 많을 수록 영향이 크다
- Z-Score 정규화: 이상값 문제를 피하기 위한 정규화, 평균 대비 표준편차가 얼마나 떨어져 있는지를 점수화하여 정규화
- 소수 스케일링(Decimal Scaling): 특성값의 소수점을 이동하여 데이터 크기를 조정하는 정규화 기법
- 데이터를 정해진 구간으로 변환 (ex. 0
- 속성 생성(Attribute/Feature Construction): 데이터 통합을 위해 새 속성 또는 특징을 생성
-
데이터 비식별화
- 데이터 보안 관리
- 데이터를 수집, 저장, 처리, 분석 시 개인정보 포함 여부, 데이터 연계 시 보안, 실제 분석 진행 및 완료 후 보안 고려
- 빅데이터 보안
- 데이터 수집 기술 취약성: 수집기의 보안 설정, 사용자 인증, 계정 관리 등 검토
- 수집 서버 및 네트워크 보안: 수집 서버의 DMZ, 방화벽, 접근 제어 등 검토
- 개인정보 및 기밀 정보 유출 방지: 암호화 처리 및 보안 강화
- 데이터 저장소 취약성: HDFS의 비활성화 데이터가 암호화 대상 여부, 사용자 보안 인증 강화, 데이터 접근 제어 등 강화
- 빅데이터 보안 등급 분류: 기밀 - 민감 - 공개 등의 보안 등급 설정
- 보안 모니터링: 시스템 관리자 권한 설정, 주기적 모니터링
- 내부 사용자의 윤리 의식: 데이터 유출 방지
- 외부 침입자 차단, 보안 로그 관리 및 권한 통제
- 데이터 비식별화
- 수집된 데이터의 개인정보 일부 또는 전부를 삭제 또는 대체하여 다른 정보와 결합하여도 개인을 식별하지 못하도록 조치
- 처리 기법
- 가명 처리(Pseudony misation)
- 직접 식별할 수 없는 다른 값으로 대체, 성명 및 고유 특징에 적용
- 휴리스틱 익명화(정해진 규칙을 이용), K-익명화(같은 속성을 가진 데이터 K개 이상 유지하여 공개), 암호화(알고리즘을 적용하여 암호화, key 보안 고려 필요), 교환방법(미리 정해진 변수 집합에 대해 레코드와 연계하여 교환)
- 총계 처리(Aggregation)
- 개인정보에 대해 통곗값을 적용, 특정 개인 판단 불가, 통계 분석에 용이, 정밀한 분석은 어려움, 수량이 어느정도 있어야 함
- 총계처리 기본 방식(집계 처리), 부분집계(부분 그룹만 비식별), 라운딩(올림, 내림), 데이터 재배열(개인정보와 연관 되지 않도록 재배열)
- 데이터 값 삭제(Data Reduction)
- 특정 데이터 값 삭제, 분석 다양성, 유효성, 신뢰성 저하
- 속성값 삭제(민감 속성 삭제), 부분 삭제(해당 속성의 일부 값 삭제), 데이터 행 삭제(속성의 구별이 뚜렷한 행 삭제), 단순 익명화(준 식별자 제거)
- 범주화(Data Suppression)
- 단일 식별 정보를 그룹의 대표값 또는 구간값으로 변환, 다양한 통계 분석 가능, 특정 분석 결과 도출 어려움, 데이터 범위 구간이 커야함
- 범주화 기본(평균 또는 범주 값으로 변환), 랜덤 올림(임의의 수 기준으로 올림 또는 내림), 범위(임의의 수 기준으로 범위 설정, 분포로 표현), 세분 정보 제한(민감 항목을 상한, 하한 코딩, 구간 재코딩), 제어 올림(행과 열이 맞지 않는 것을 제어하여 랜덤 올림)
- 데이터 마스킹(Data Masking)
- 개인 식별 정보에 대해 부분 또는 전체에 대체 값(*)으로 변환, 데이터 구조 변화가 없음, 마스킹 수준이 낮으면 예측 가능
- 임의 잡음 추가(임의의 숫자 등의 잡음 추가), 공백과 대체(비식별 대상 데이터를 공백으로 바꾼 후 대체법 적용하여 공백을 채움)
- 가명 처리(Pseudony misation)
- 비식별 조치
- 사전검토: 개인정보 해당 여부 검토
- 비식별 조치: 식별자, 목적과 관련 없는 속성자는 원칙적으로 삭제, 여러 비식별 조치 방법을 이용하여 활용
- 적정성 평가: 기초 자료작성 → 평가단 구성 → 평가 수행(비식별 수준 적정성 평가) → 추가 비식별 조치 → 데이터 활용
- 사후관리: 비식별 정보 안전조치(관리적/기술적 보호조치), 재식별 가능성 모니터링(새로운 정보 생성시 모니터링)
- 데이터 보안 관리
-
데이터 품질 검증
- 데이터 유효성
- 정확성(정확, 사실, 적합, 필수, 연관성), 일관성(정합, 일치, 무결성)
- 데이터 활용성
- 유용성(충분, 유연, 사용, 추적성), 접근성, 적시성, 보안성(보호, 책임, 안정성)
- 변환 이후 품질 검증
- 수집 데이터 분석: 수집 → 메타데이터 수집 → 메타데이터 분석(불일치 정보 관리) → 데이터 속성 분석
- 데이터 속성(유효성) 분석
- 누락 값 분석, 허용 범위 분석, 허용 값 목록 분석, 문자열 패턴 분석, 날짜 유형 분석, 유일 값 분석, 구조 분석(관계, 참조 무결성, 구조 무결성 분석)
- 일반적으로 정형 데이터에 대해 수행
- 데이터 양식, 규칙을 적용하기 위해 정규 표현식을 통한 유효성 검증 수행
- 품질 검증 방안
- 수집 방식, 모델, 기능, 제약 사항, 수집된 데이터의 유형 등을 수집하여 품질 관리
- 수집 데이터의 복잡성, 완전성, 유용성 등에 대한 품질 검증 기준 정의
- 복잡성: 구조, 형식, 자료, 계층
- 완전성: 설명 유무, 개체/변수, 메타데이터
- 유용성: 처리 용이성, 자료 크기, 제약 사항
- 시간적 요소 및 일관성: 시간적 요소, 일관성, 타당성, 정확성
- 품질 검증 기준에 따라 품질 관리 시스템을 활용하여 품질 검증 수행
- 데이터 유효성
데이터 적재 및 저장
-
데이터 적재
- 데이터 적재 아키텍처
- 아키텍처 정의란 요구사항을 구현하기 위한 기반 기술 정의
- 요구사항 정의
- 장비 요구사항 정의: 서버 장비 규격(네임노드, 데이터노트, 분석 서버, 수집 서버), 네트워크 장비 규격(라우터, 스위치 등), 스토리지 장비 규격(SAN-RAID, NAS 등) 정의
- SW도입 요구사항 정의: On-premise(자체 보유 전산실 운영) 또는 상용 클라우드 서비스
- 성능 요구사항 정의: 서버, 네트워크, DBMS, 응용 시스템
- 인터페이스 요구사항 정의: 내부 또는 외부 연계 시스템 고려
- 하드웨어 아키텍처 정의
- 서버 노드 아키텍처: Name Node(메타데이터 관리 서버), Data Node(실제 데이터 저장 및 처리)로 구분
- 데이터 아키텍처: RDB(정형데이터, 엄격 트랜잭션 요구 데이터), NoSQL(비정형 데이터), 분산 파일 시스템 등 처리하고자 하는 데이터 유형 성격 검토 및 선택
- 네트워크 아키텍처: 목표 시스템 네트워크 구성, 개별 장비 네트워크 환경 정의(각 서비는 인터페이스 카드NIC를 장착)
- SW 아키텍처 정의
- 데이터 수집, 적재, 저장, 처리, 분석, 활용 단계, 자원 관리, 모니터링, 사용자 인터페이스 정의
- 하둡 도입 검토: 분산 파일 시스템, 분산 병렬 처리
- In-Memory DB 도입 검토: 데이터 저장 스토리지가 메인 메모리를 이용하는 DBMS, 접근 속도가 빠르고, 검색 조회 알고리즘이 단순
- 데이터 분석 플랫폼 적용 검토: 대용량 데이터로부터 여러 기법을 이용하여 데이터 간 관련성 분석 및 필요 정보 추출
- 데이터 시각화 적용 검토: 데이터의 효과적인 의미 전달 목적
- 데이터 적재
- 데이터 수집 이후, 시스템에 적재하는 것
- 데이터 유형과 실시간 처리 여부에 따라 시스템이 구분된다
- 데이터 적재 도구
- Fluentd(플루언티드): 루비 언어를 사용하는 크로스 플랫폼 오픈 소스 데이터 수집 SW
- Flume: 많은 양의 로그 데이터를 Event와 Agent를 활용하여 분산형 로그 수집
- Scribe: 다수 서버로부터 실시간 스트리밍 로그 데이터를 수집하여 분산 시스템에 데이터 저장, 대용량 실시간 로그 수집
- Logstash: 모든 로그 정보를 수집, 저장소에 출력하는 시스템
- 데이터 적재 아키텍처
-
데이터 저장
-
대용량 데이터 집합을 저장하고 관리하는 시스템으로 큰 저장 공간, 빠른 처리, 확장성, 신뢰성, 가용성 등을 보장
-
저장 기술
-
분산 파일 시스템
-
구글 파일 시스템(GFS)
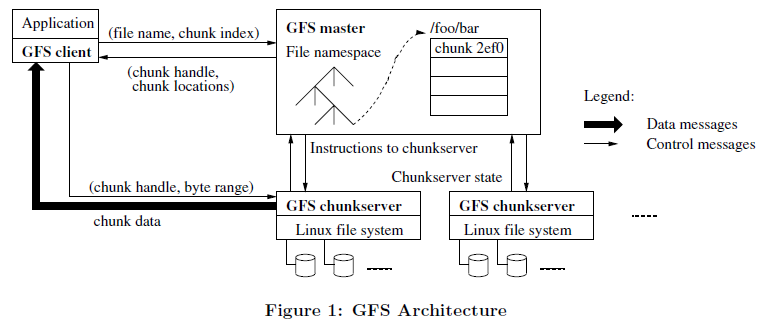
- 구글의 대규모 클러스터 서비스 플랫폼의 기반 파일 시스템
- Chunk(64MB 고정)들로 파일을 나누어서 청크 서버에 각 청크와 복제본을 분산 저장
- Client, Master, Chunk Server로 이루어짐
- Client: 파일 읽기/쓰기 동작을 요청하는 Application, 자체 인터페이스 지원
- Master: 단일 마스터 구조, 파일 시스템의 Name space, 파일-청크 매핑 정보, 청크 서버 위치 정보 등 모든 메타데이터를 관리
- Chunk Server: 로컬에 청크 저장, 클라이언트에서 입출력 요청 시 처리, 주기적으로 청크 서버의 상태를 하트비트 메세지로 마스터에 전달
-
HDFS(Hadoop Distributed File System)

- 대용량 파일을 분산된 서버에 저장하고, 빠르게 처리할 수 있게 하는 분산 파일 시스템
- 저사양의 다수 서버를 이용하여 스토리지 구성 가능, NAS, DAS, SAN 등에 비해 비용적으로 효율
- 블록 구조의 파일 시스템, 특정 크기(하둡2.0: 128MB)로 나누어서 분산 서버 저장
- 하나의 Name Node, 하나 이상의 보조네임노드, 다수의 Data Node로 구성
- Name Node: 모든 메타데이터 관리, Master-Slave 구조의 Master역할, 데이터 노드 상태 체크(하트비트), 블록 상태 체크
- Secondary Name Node: 상태 모니터링 보조, 주기적으로 Name Node의 파일 시스템 이미지 스냅샷 생성
- Data Node: slave역할, 데이터 입출력 요청 처리, 블록 3중 복제 저장(데이터 유실 방지)
-
러스터(Lustre)

- 객체 기반의 클러스터 파일 시스템
- Client File System, Metadata Server, 객체 저장 서버로 구성
- 계층화된 모듈 구조, TCP/IP 등의 네트워크 지원
- Client File System: Linux VFS(Virtual File System)에 설치 가능한 파일 시스템, 서버들과 통신하며 파일 시스템 인터페이스 제공
- Metadata Server: 파일 시스템의 이름 공간과 메타데이터 관리
- 객체 저장 서버: 파일 데이터 저장, 클라이언트 객체 입출력 요청 처리, 스트라이핑 방식으로 분산 및 저장(Segment로 분할하여 디스크 장치에 분산)
-
-
DB 클러스터
- 하나의 DB를 여러 개의 서버에 분산하여 구축
- 데이터 통합 시, 성능, 가용성 향상을 위해 DB Partitioning또는 Clustering을 이용
- 구성 형태에 따라 단일 서버 파티셔닝, 다중 서버 파티셔닝 구분
- 클러스터 종류
- 공유 디스크 클러스터(Shared Disk Cluster): 논리적으로 데이터를 공유하여 모든 데이터에 접근 가능하게 하는 방식, SAN필요, 모든 노드가 데이터 수정 가능(동기화 필요), 높은 수준의 고가용성, 하나의 노드만 살아도 서비스 가능
- 무공유 디스크 클러스터(Shared Nothing Cluster): 각 인스턴스들을 로컬 디스크에 저장, 노드간 공유 없음, 노드 확장 제한 없음, 각 노드 장애 발생 경우 대비 필요
- Oracle RAC(공유 클러스터), IBM DB2 ICE(무공유), SQL Server(연합 DB, 여러 노드 확장 가능, Failover-장애 발생시 대체 작동 제공, Active-standby), MySQL(비 공유, 관리, 데이터, MySQL노드로 구성, 데이터 복제- 동기화, 데이터 노드간 네트워크 구성)
-
NoSQL(Not Only SQL)
- 데이터 저장에 고정된 테이블 스키마가 필요하지 않고, join 연산이 없고, 수평적 확장 가능한 DBMS
- 관계형 모델(RDBMS)을 사용하지 않는 데이터 저장소 또는 인터페이스
- 대규모 데이터를 처리하기 위한 기술 - 확장성, 가용성, 높은 성능 제공
- Schema-less: 고정된 스키마 없이 DB 레코드에 필드 추가
- 특성
- Basically Available: 언제든지 접근 가능, 항상 가용성
- Soft-State: 외부 전송 정보를 통해 노드 상태 결정, 일관성 보장 x
- Eventually Consistency: 일정 시간이 지나면 데이터 일관성 유지
- 유형
- Key-Value Store: Unique Key에 하나의 Value를 가진 형태, 키 기반 Get/Put/Delete 제공(ex: Redis, DynamoDB)
- Column Family Data Store: Key안에 (column, value)조합의 여러 필드를 가짐, 테이블 기반, 조인 미지원, 컬럼 기반, 구글 빅테이블 기반(ex: HBase, Cassandra)
- Document Store: Value 타입이 Document 타입(XML, Json, YAML)인 DB(ex: MongoDB, Couchbase)
- Graph Store: Semantic Web(Ontology 의미적 상호 운용성 이용 서비스 기능 자동화 웹)에서 활용되는 그래프로 데이터 표현(ex: Neo4j, AllegroGraph)
- CAP
- 분산 컴퓨팅 환경은 아래의 3가지 특징 중, 두가지만 만족할 수 있다는 이론
- Availabilty(유효성): 모든 클라이언트가 읽기 쓰기가 가능, 하나의 노드에 장애가 나면 다른 노드에 영향 x
- Consistency: 데이터 일관성
- Partition tolerance(분산 가능): 물리적 네트워크 분산 환경 동작, 데이터 손실이 생겨도 시스템은 정상 동작
- 구글 빅테이블(GCP에서 저장소로 사용), HBase, AWS simpleDB, Azure SSDS(SQL Server Data Service)
-
병렬 DBMS: VoltDB, SAP HANA
-
네트워크 구성 저장 시스템: SAN(Storage Area Network), NAS(Network Attached Storage)
-
클라우드 파일 저장 시스템: AWS S3
-
-
저장 고려사항
- 요구사항 분석: 요구사항 수집 → 분석 → 명세 → 검증
- 데이터 저장의 안정성, 신뢰성 확보 필요 - 용량산정, 데이터 파악, 시스템(Private/Public Cloud) 구축 방안
- 유형별 데이터 저장방식
- 정형(RDB, 스프레드시트) - RDB(Oracle, MSSQL, MySQL, Sybase)
- 반정형(HTML, XML, JSON) - RDB, NoSQL(MongoDB, Redis, HBase)
- 비정형 - NoSQL, HDFS
- 저장방식 선정: 저장 기술의 기능성, 분석 방식 및 환경, 분석 대상 데이터 유형, 기존 시스템과의 연계
- 저장방식 결정: 선정 고려 사항을 분석하여 선정 결과서에 작성 및 공유
-
Reference
- ETL: https://rivery.io/etl-vs-elt-whats-the-difference/
- Scrapy: https://iosroid.tistory.com/28
- Kafka: https://docs.confluent.io/current/kafka/introduction.html
- Chukwa: https://kmongcom.wordpress.com/2014/03/16/하둡-척와hadoop-chukwa-초보-가이드-기본/
- Flume: http://taewan.kim/post/flume_images/
- GFS: https://maengdev.tistory.com/29
- HDFS: https://628story.tistory.com/3
- Lustre: https://wiki.lustre.org/File:Lustre_File_System_Overview_(DNE)_lowres_v1.png
반응형
'IT > Certificate' 카테고리의 다른 글
| [Tensorflow Certificate] 준비 및 후기 (13) | 2020.12.28 |
|---|---|
| 빅데이터 분석기사 필기 - 빅데이터 분석 기획 #2 (0) | 2020.11.19 |
| 빅데이터 분석기사 필기 - 빅데이터 분석 기획 #1 (0) | 2020.11.12 |





_lowres_v1.png){kind=link}