머신러닝 (1) - 머신러닝을 사용하는 이유와 분류 그리고 문제점

Writer: Harim Kang
머신러닝 - 1. The Machine Learning Landscape
해당 포스팅은 머신러닝의 교과서라고 불리는 Hands-On Machine Learning with Scikit-Learn & Tensorflow 책을 학습하며 정리하고, 제 생각 또한 함께 포스팅한 내용입니다.
https://www.oreilly.com/library/view/hands-on-machine-learning/9781491962282/ch01.html의 내용과 제 조사 및 생각을 함께 정리한 포스팅입니다.
오늘의 포스팅은 Chapter 1. The Machine Learning Landscape 단원이며, 해당 단원은 머신러닝의 전체적인 부분을 요약하고, 분류한 개요라고 볼 수 있습니다. 가지고 있는 데이터를 사용하여 어떤 방식으로 머신러닝 알고리즘을 택할 것인지에 대한 가이드를 제시합니다.

Machine Learning(머신러닝) 이란?
해야 할 일(문제) T에 대해서, 그동안 T를 해왔던 경험 E를 바탕으로, 학습하는 System Program을 의미합니다. 해당 Program은 Performance(성능) P를 통해 평가합니다.
쉽게 말해서, 해결하고자 하는 문제 T와 T와 관련되어 축적된 데이터 E를 사용하여 이후의 T를 해결하고자 하는 것을 의미합니다. 이는 특정한 기준으로 설정된 성능 P를 통해 평가할 수 있어야 합니다.
왜 머신러닝을 사용하고자 하는가?
기존의 프로그래밍 방식은 어떠한 규칙을 Case로 나누어서 대응하는 코드를 하나하나 입력하는 방식이었습니다. 새로운 Case가 발생하면, 직접 Case에 대응하는 코드를 추가로 작성해야 했죠.
머신러닝 접근법은 기존의 Data (E)를 학습하면서, 각각의 Case (T) 들에 대한 패턴과 규칙들을 찾아내는 방법입니다. 이는 새로운 Case가 발생하면, 학습된 패턴과 규칙들을 바탕으로 따로 코드를 작성하지 않아도 대응할 수 있는 거죠.
기존의 방식 VS 머신러닝
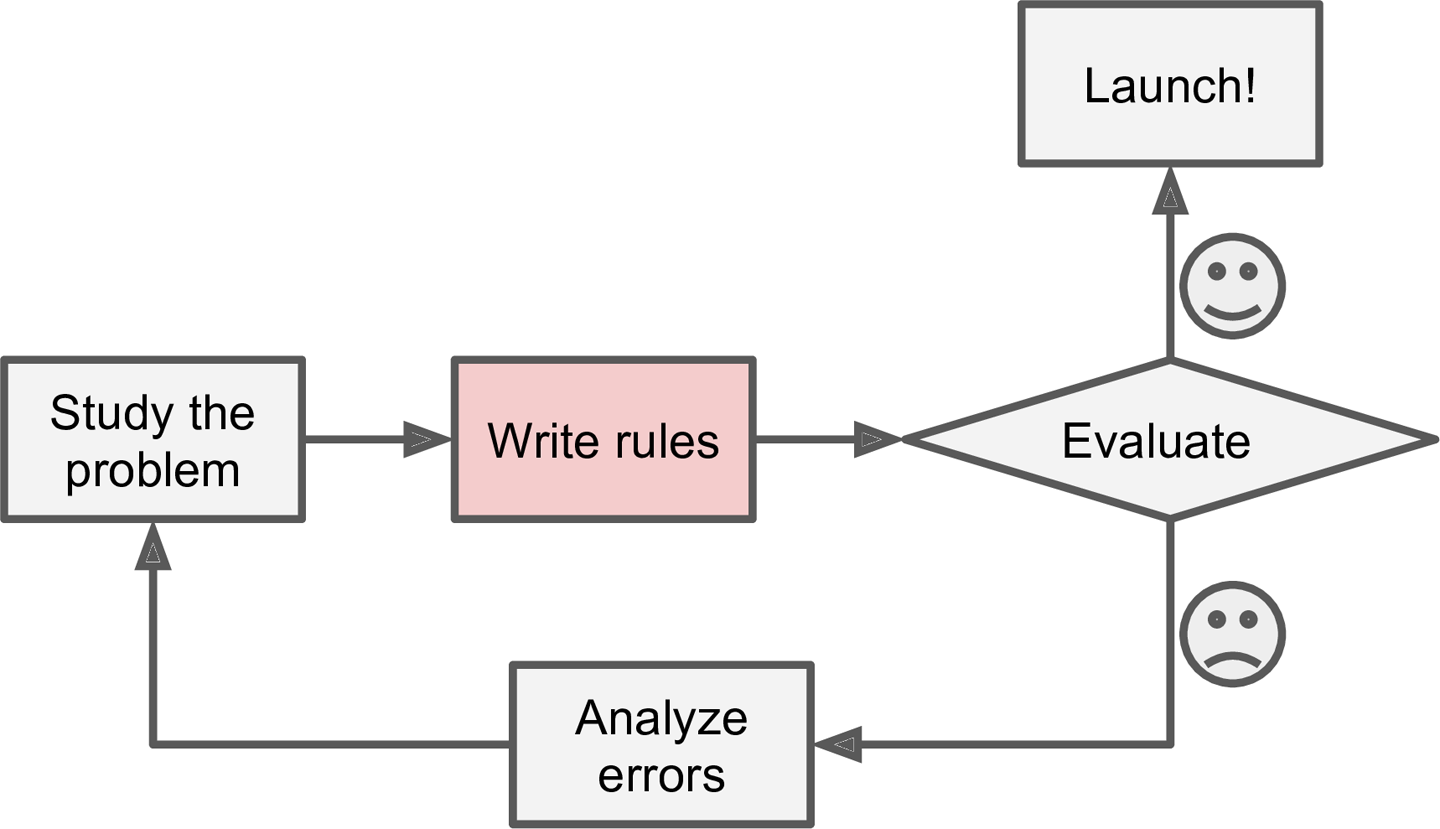
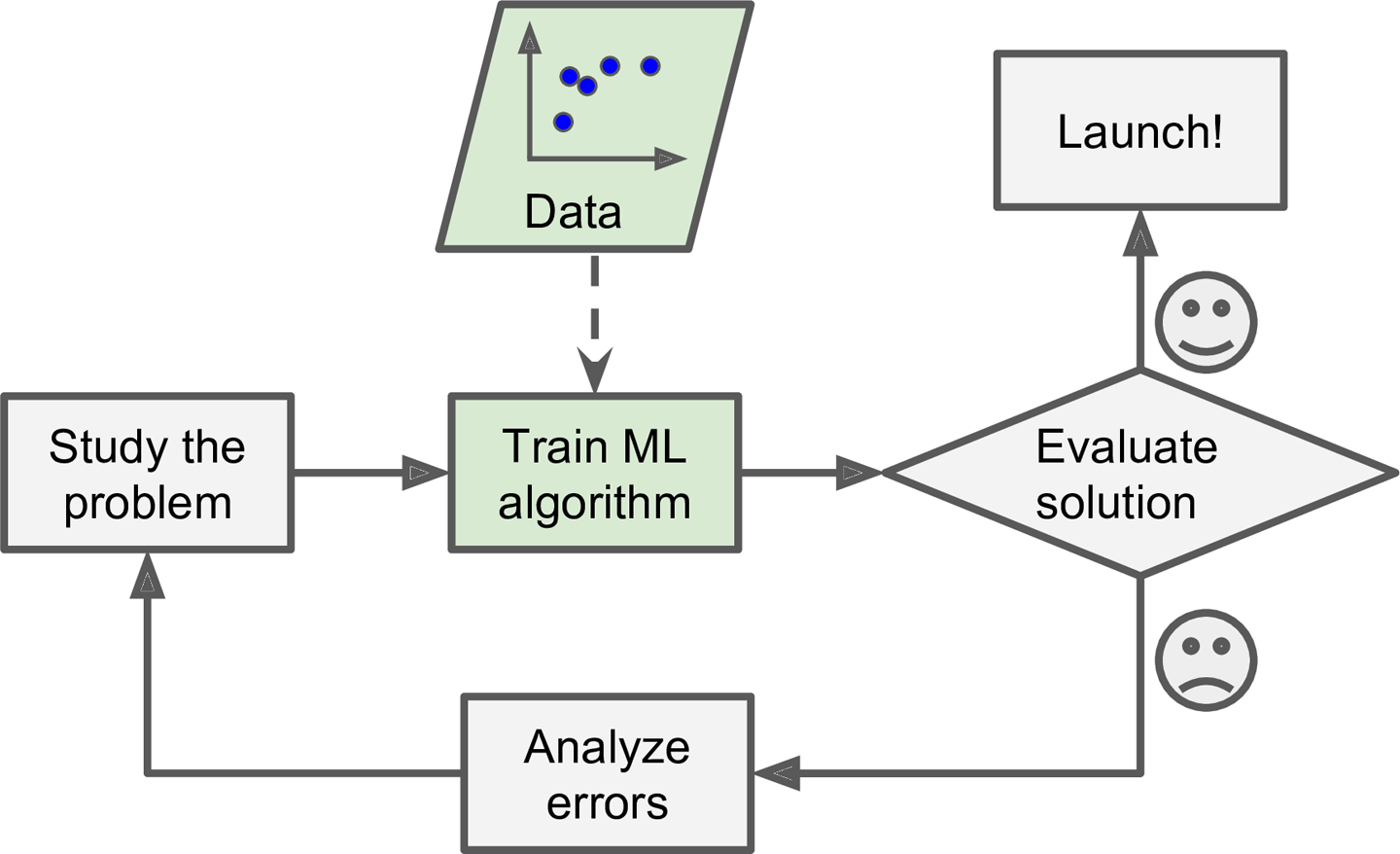
- 머신러닝은 기존의 프로그래밍에 비해 새로운 규칙 또는 패턴에 대한 유지보수가 쉽습니다.
- 머신러닝은 새로운 변수에 대처가 가능합니다.
- 머신러닝은 상대적으로 더 짧은 Code로 작성 가능합니다.
- 머신러닝은 복잡한 문제에 적용하기에 적합하다고 볼 수 있습니다.
- 평가를 통해 꾸준하게 개선이 될 수 있습니다.
머신러닝 시스템의 분류
머신러닝은 여러 기준에 따라 다양한 분류체계를 가지고 있습니다. 개발자는 머신러닝 시스템 분류를 이해하고, 적절한 방식의 알고리즘을 선정하여 사용하여야 합니다.
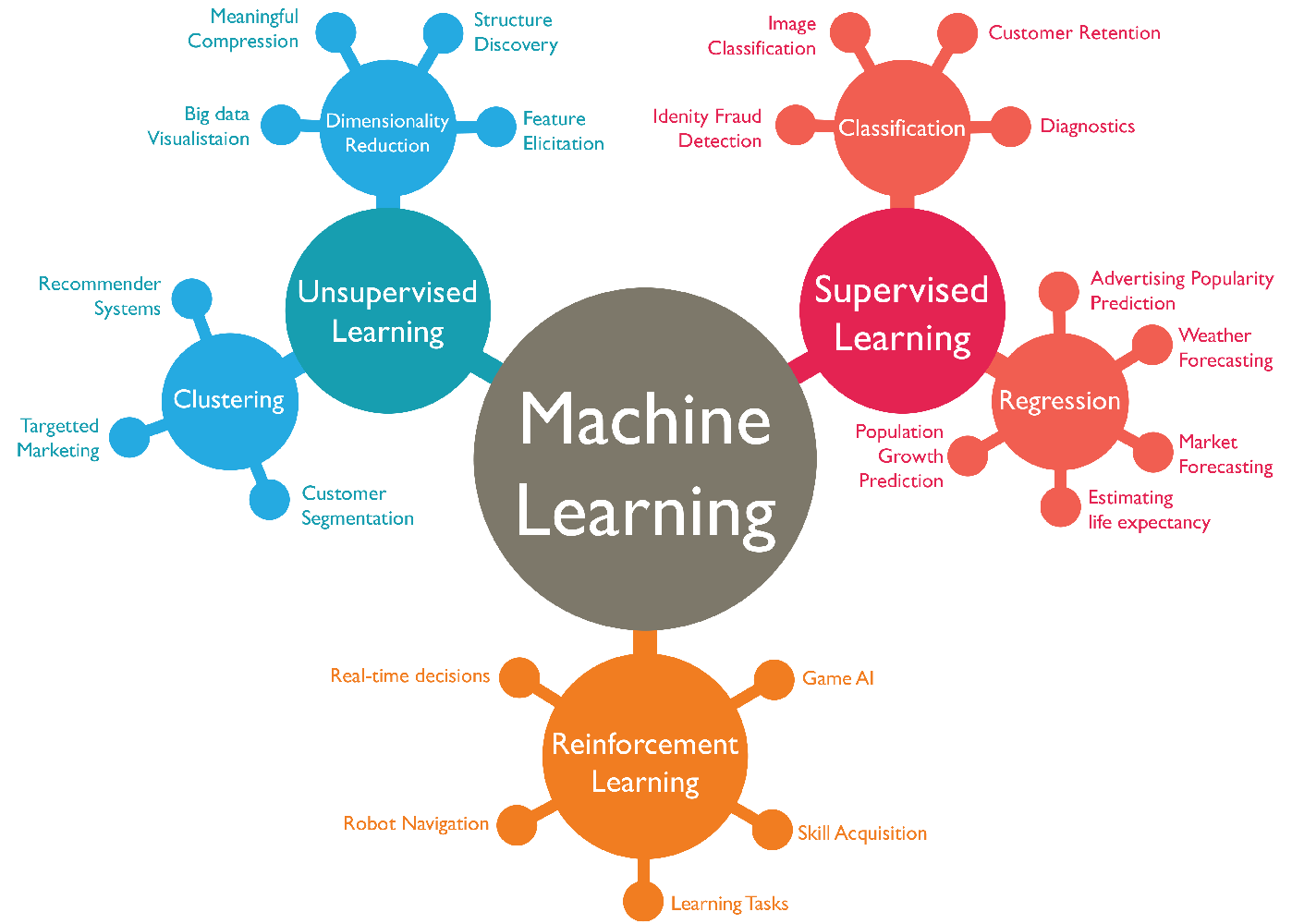
-
Human Supervision (사람이 부여한 정답)이 필요한가?
-
Supervised Learning : Human Supervision이 있는 경우
Supervised Learning은 각각의 학습을 위한 데이터들이 Label을 가지고 있는 경우 사용됩니다. Label이란, 문제와 관련된 여러 Instance들이 있을 때, 해당 data가 의미하는 정답이라고 볼 수 있습니다.

A labeled training set for supervised learning (e.g., spam classification) 위의 그림은 스팸 메일 분류를 위한 방식을 그림으로 표현한 것입니다. 메일안의 내용들 (Instance)이 있고, 각각의 메일들에는 기존에 스팸을 구분해 놓은 Label이 있습니다. 여기서 Label은 스팸인지 아닌지 두가지 경우를 나누어서 나타내었습니다. 기존의 모든 메일 데이터를 Training Set 학습 데이터 세트로 학습시켜서 새로운 메일이 들어왔을 때, Label이 무엇인지를 예측하는 방법입니다.
-
Classification : 분류
기존 Dataset의 Label들이 class로 나누어진 경우, 새로운 데이터는 어떤 class에 속하는 지를 찾아내는 방식입니다. 위의 스펨 분류 예제는 Classification입니다.
-
Regression : 회귀
Label들이 수치로 이루어진 경우, 새로운 데이터는 어떠한 수치를 가지게 될지 예측하는 방식을 Regression이라고 합니다.
-
-
Unsupervised Learning : Human Supervision이 없는 경우
Supervised와 다른 점은 Label이 없는 학습 데이터를 사용하여 기존의 데이터가 어떠한 형태를 지니고 있는지를 보고 판단하는 방식입니다.

An unlabeled training set for unsupervised learning 기존 데이터의 다양한 Feature들을 다양한 차원으로 분석하여 집단을 형성하는 방식입니다. Clustering 방식이 대표적입니다. 위와 같은 그림의 학습 데이터는 아래의 Clustering 그림으로 나누어집니다.

Clustering 아래는 Unsupervised Learning의 알고리즘 분류입니다.
- Clustering Algorithm
- K - Means
- Hierarchical Cluster Analysis (HCA)
- Expectation Maximization
- Visualization and dimensionality reduction
- Principal Component Analysis (PCA)
- Kernel PCA
- Locally-Linear Embedding (LLE)
- t-distributed Stochastic Neighbor Embedding (t-SNE)
- Association rule learning
- Apriori
- Eclat
- Clustering Algorithm
-
Semi-supervised Learning
이름 그대로 supervised learning과 unsupervised learning을 합친 방식입니다. 몇몇의 Label이 있는 데이터와 많은 양의 Label이 없는 데이터를 사용하여 학습하는 방식입니다.
Semisupervised learning -
Reinforcement Learning
Agent가 환경을 인지하고, 정책(Policy)에 맞게 현상황에서의 행동을 선택합니다. 선택한 행동을 수행하고, 보상(Reward) 또는 페널티(Penalty)를 부여하여, 정책을 결과에 맞게 업데이트합니다. 앞의 행동을 계속 반복하여 최적의 정책을 위해 계속 업데이트해나가는 과정을 강화 학습 (Reinforcement Learning)이라고 합니다.
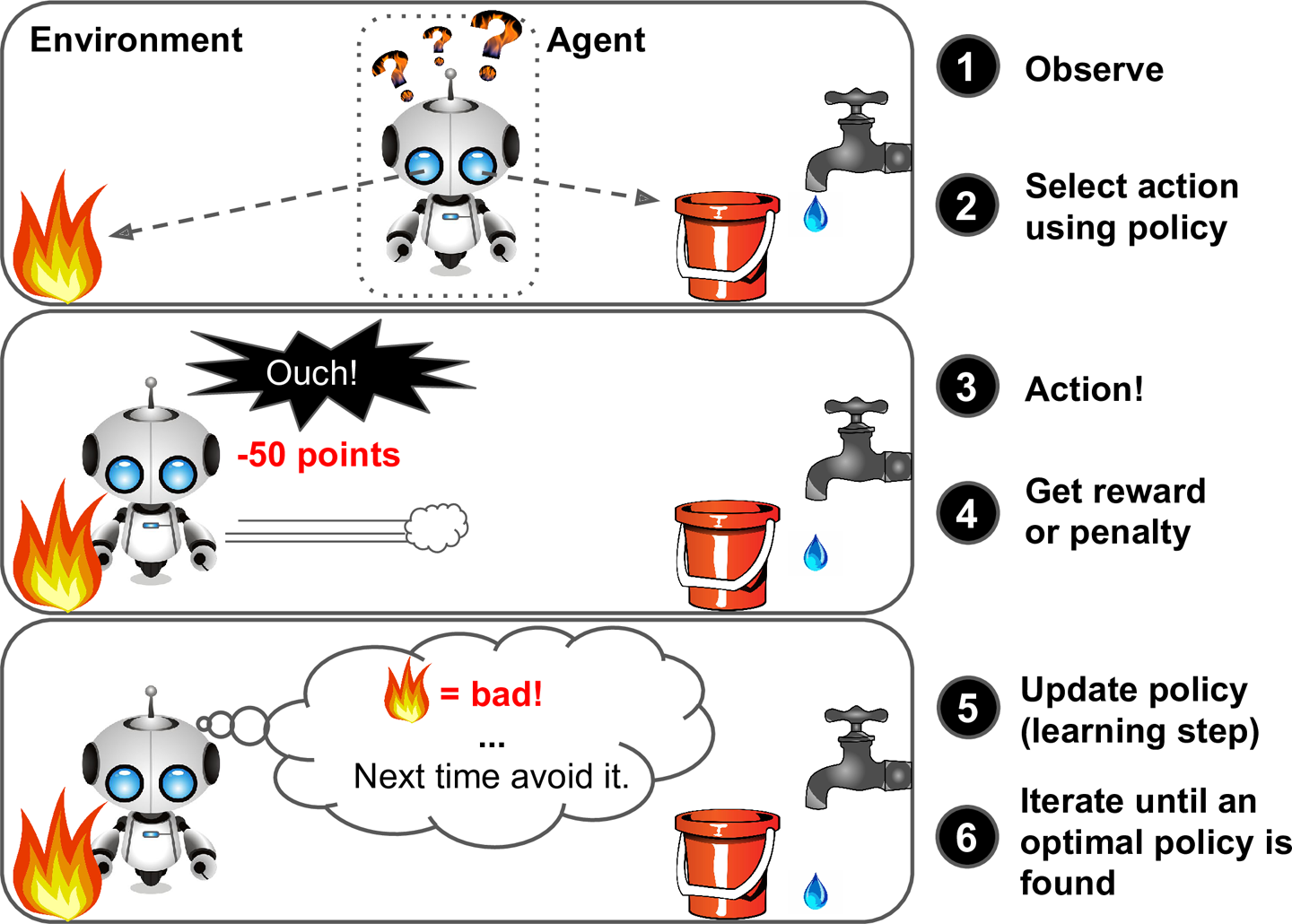
Reinforcement Learning Agent와 Policy를 선정하는 것이 핵심이며,
Agent는 환경 인지가 가능하고, 행동을 선택 및 수행하며, 보상 또는 손해라는 결과를 얻어서 이를 통해 학습하여 최적의 결과를 찾아가는 방식으로 업데이트합니다.
대표적인 예로는 DeepMind의 AlphaGo가 있습니다.
-
-
학습은 언제 하는가? : 점진적인 학습을 하는가에 대한 여부를 분류
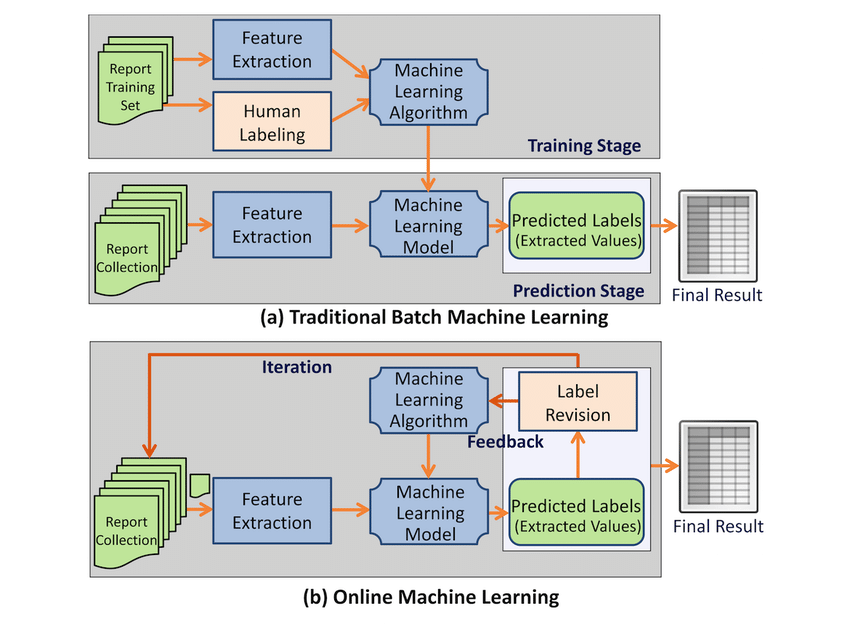
Online machine learning versus batch learning Workflow -
Batch Learning
점진적으로 학습을 하지 않고, 특정 시점에 사용 가능한 모든 데이터를 사용하여 학습을 하는 방식입니다. 모여있는 모든 학습 데이터를 학습하므로, 많은 시간과 컴퓨팅 파워가 필요합니다. 일반적으로 Offline Learning이라고도 부릅니다.
새로운 데이터로의 학습을 원하면 전체 데이터 세트에 대하여 새로운 모델을 생성하여야 합니다. 그 후 시스템의 모델을 교체하는 방식입니다.
-
Online Learning
새로운 데이터 Instance들을 순차적으로 개별적 또는 소규모의 그룹으로 점진적 학습을 하는 방식입니다. Batch Learning에 비해 소규모로 학습을 진행하여서, Mini-Batch라고도 합니다. 각 학습 단계는 빠르고 상대적으로 적은 컴퓨팅 파워를 필요로 합니다. 새로운 데이터가 들어오면 바로 학습을 시작합니다.
Online learning 빠르고 자율적으로 변화해야 하는 시스템에 적합한 훈련 방식으로, 컴퓨팅 리소스가 제한적일 때에도 적합합니다. 학습되지 않은 데이터를 저장할 공간을 절약할 수 있습니다.
Online Learning은 방대한 양의 데이터 세트에서도 사용될 수 있습니다. (모든 데이터 세트가 메인 메모리에 다 들어가지 않는 경우, out-of-core Learning이라고도 부릅니다.) 전체 데이터 세트를 가능한 만큼 메인 메모리로 나누어서 점진적으로 학습하는 방식입니다. 이때, 데이터를 나누어서 학습을 진행하는 것은 Offline에서 진행됩니다. 여기서 말하는 Offline은 Live의 반대로 생각하면 되며, 거대한 데이터 자체가 새로운 데이터이기 때문에 전체적으로 보았을 때는 Online적인 Learning입니다.
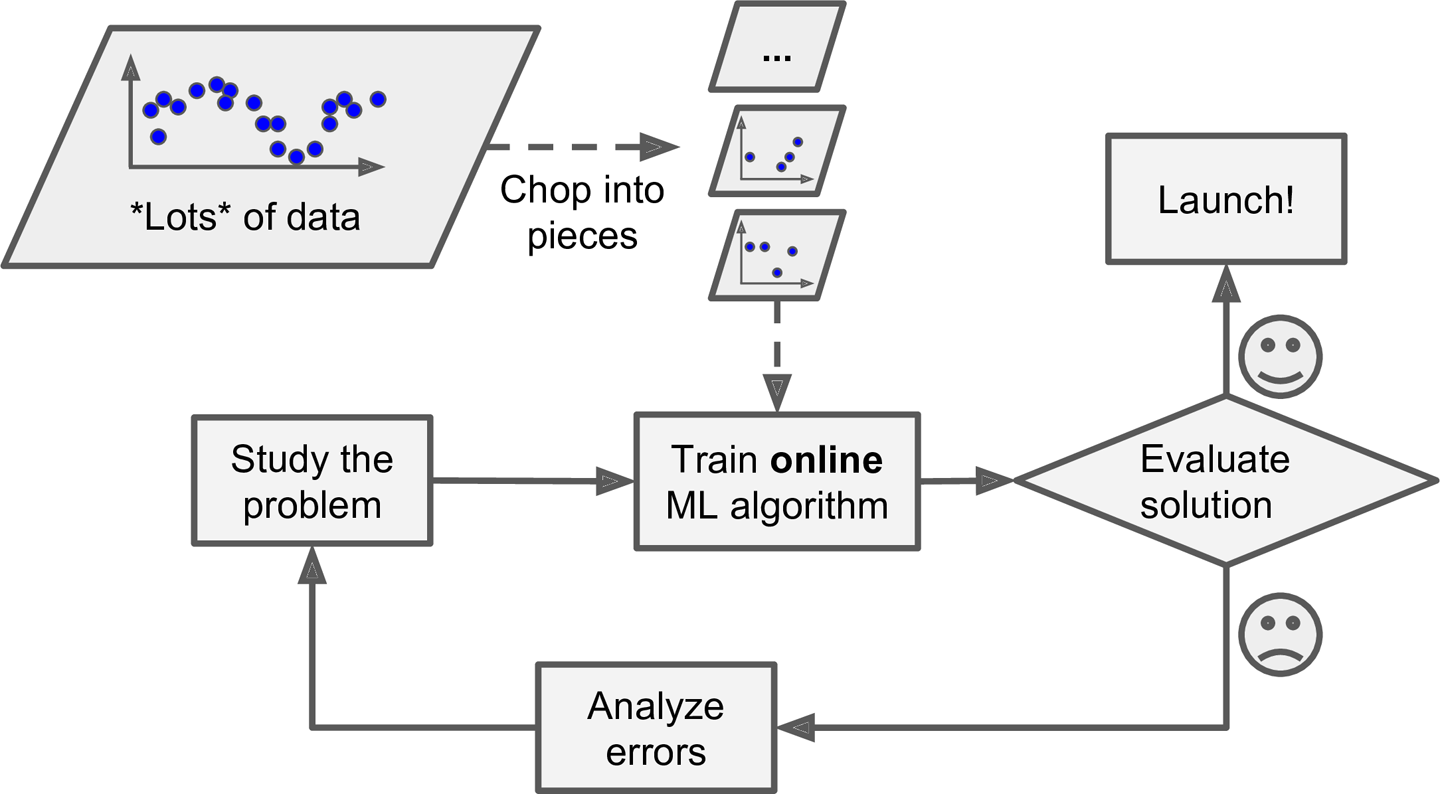
Using online learning to handle huge datasets Online Learning에서 중요한 변수 중 하나는 Learning Rate입니다. Learning Rate는 High Rate와 Low Rate로 나뉩니다..
-
High Rate
시스템이 새로운 데이터에 빠르게 적응하지만, 이전 데이터를 빠르게 잊어버리는 경향이 생깁니다. 노이즈 데이터나 잘못된 데이터에 반응하여 잘못된 방향으로의 학습 확률이 높아집니다.
-
Low Rate
이전 데이터에 대해 관성(유지하는 성질)이 높아진다. 속도가 느려지지만, 새로운 데이터의 노이즈나 이상점에 대해 덜 민감하여 기존의 학습을 상대적으로 유지합니다.
-
-
-
Instance VS Model : 어떠한 것에 중점을 둘 것인가?
해당 기준은 시스템을 일반화하는 방법에 따라 학습을 분류합니다. 이는 새로운 데이터에 얼마나 잘 적용이 되었는가를 중요하게 생각합니다.
-
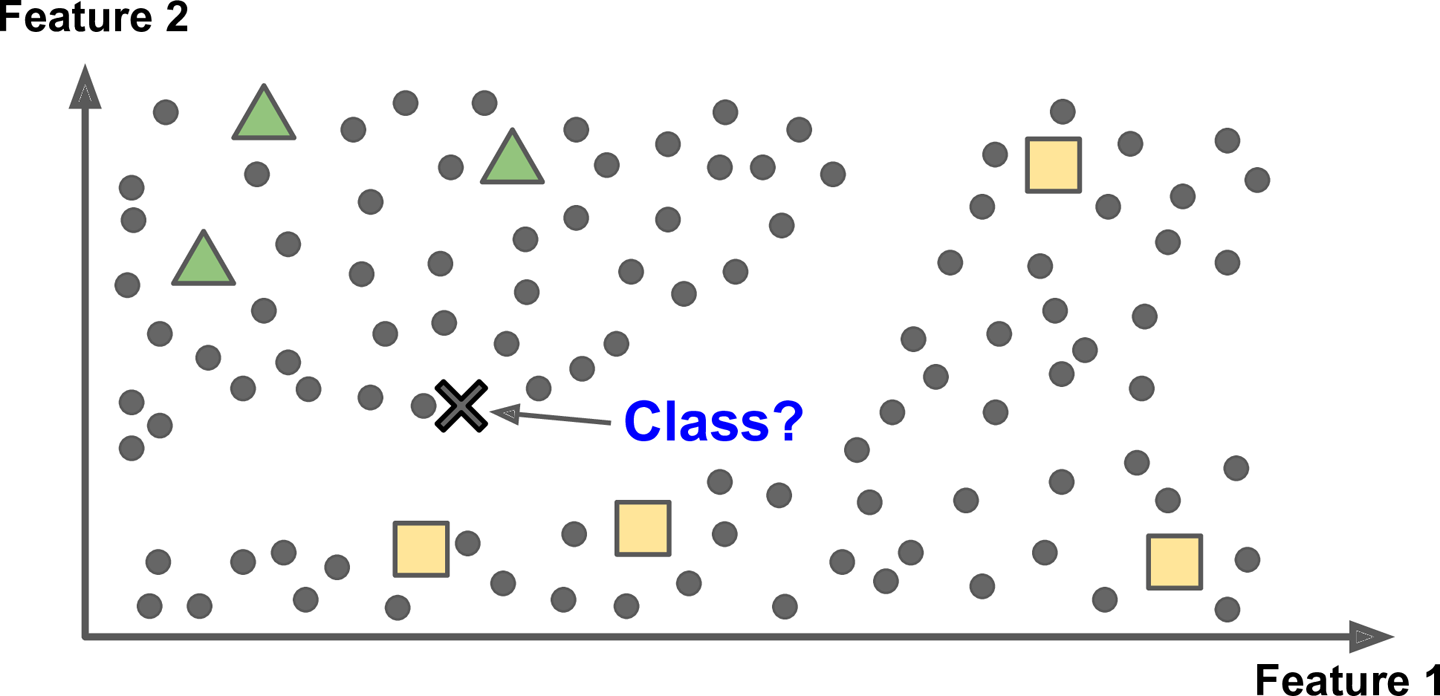
Instance-based Learning
새로운 데이터를 이미 알고 있는 데이터들과의 유사성을 측정하여 판단하는 학습 방식입니다.
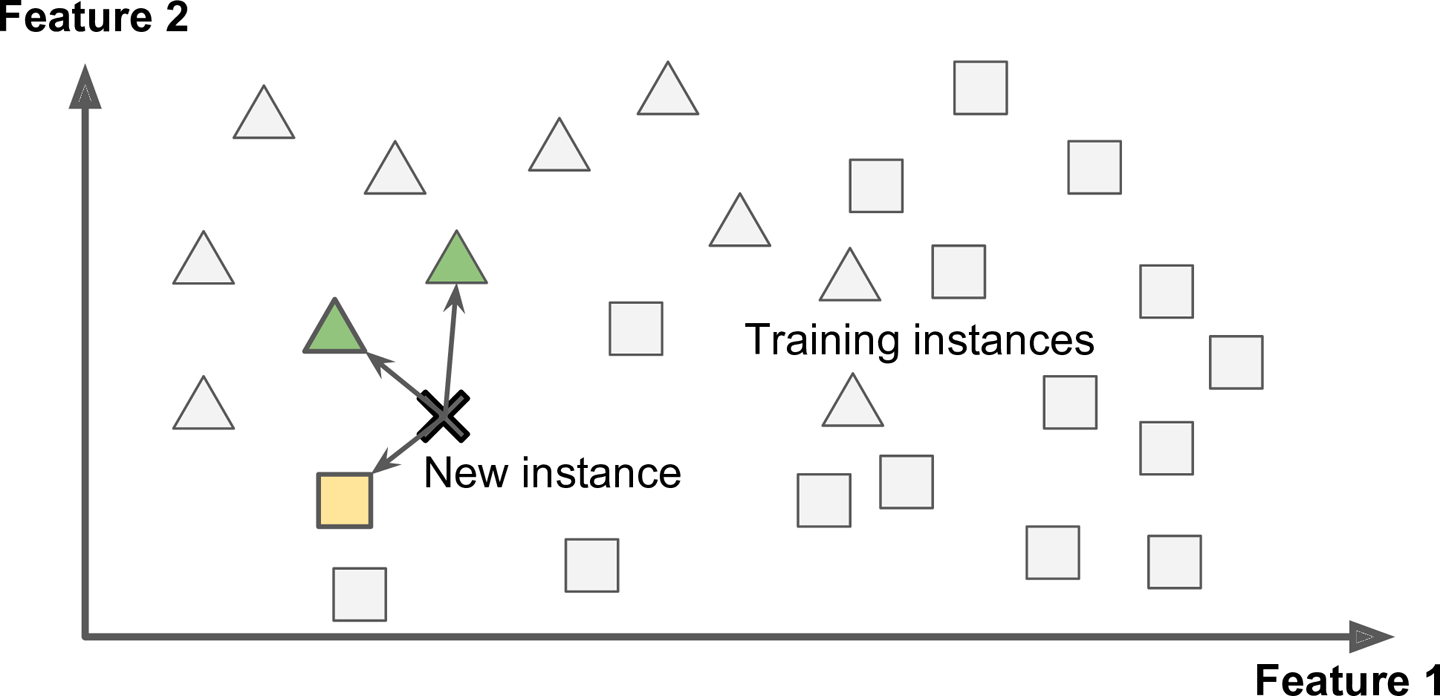
Instance-based Learning -
Model-based Learning
기존의 이미 알고 있는 데이터들을 학습하여 모델을 빌드한 후에, 해당 모델을 이용하여 새로운 데이터를 판단하는 학습 방식입니다.

Model-based Learning 요약하자면, 기존의 학습 데이터를 살펴보고, 적합한 모델을 선택하여 학습시키고, 모델을 적용하여 새로운 데이터를 예측하는 방식입니다. 이것은 일반적인 머신러닝 학습 방식입니다.
-
머신러닝이 해결해야 할 문제점
머신러닝에도 문제점이 있습니다. 이것은 물론 결과 (성능)과도 연관성이 아주 많습니다. 잘못된 예측을 하면 그것은 성능이 낮은 모델이며, 무언가 문제점을 가지고 있다는 점을 의미합니다. 머신러닝의 핵심은 데이터와 알고리즘입니다. 두 가지 관점에서 문제점이 주로 발생하며, 이를 살펴보겠습니다.
-
부족한 학습 데이터 양 (Insufficient Quality of Training Data)

Insufficient Quality of Training Data 많은 개발자, 기업들이 문제를 머신러닝을 통해 풀고자 하지만, 큰 어려움을 겪습니다. 그것은 바로 학습할 데이터가 부족하다는 점입니다. 사실 데이터의 양은 점차 늘어가면서 아주 방대한 양의 데이터가 우리 주변에 있습니다. 하지만 문제를 정의하고 해당 문제를 해결하는 데에는 뚜렷한 목적을 가지고 정제된 데이터가 필요합니다. 이러한 데이터 세트를 형성하는 것이 가장 큰 어려움입니다.
머신러닝 알고리즘은 제대로 동작하기 위해서, 많은 데이터가 필요합니다. 간단한 문제를 해결하기 위해서는 수천 개의 데이터가 기본적으로 필요하며, 더욱이 풀고자 하는 복잡한 문제들은 수백에서 수천만, 필요하다면 더 많은 데이터가 필요합니다.
-
좋지 않은 질의 데이터 (Poor - Quality Data)

Poor - Quality Data 완벽한 데이터 세트는 찾기 힘듭니다. 요구하는 사항을 만족하는 데이터가 있는 반면, errors, outliers, noises가 존재하는 데이터가 있습니다. 이러한 에러와 아웃라이어, 노이즈를 적절하게 대처하는 것은 학습에 중요한 영향을 끼칩니다.
-
연관성이 적은 특징의 사용 (Irrelevant Features)
Supervised Learning의 경우, Label이라는 정답지를 가지고 있습니다. 하지만 이 Label과 연관된 특징은 모든 특징 중의 일부일 가능성이 높습니다. 오히려 관련 없는 특징들은 Label을 예측하는 데에 방해만 될 뿐입니다. 특징들을 걸러내지 않고 학습을 한다면 성능이 낮아집니다. 이를 방지하기 위하여 아래와 같은 방식을 사용합니다.
- Feature Selection
- Feature Extraction
- 연관된 새로운 Feature를 생산하여 데이터에 추가하는 방식
-
과적합 (Overfitting)
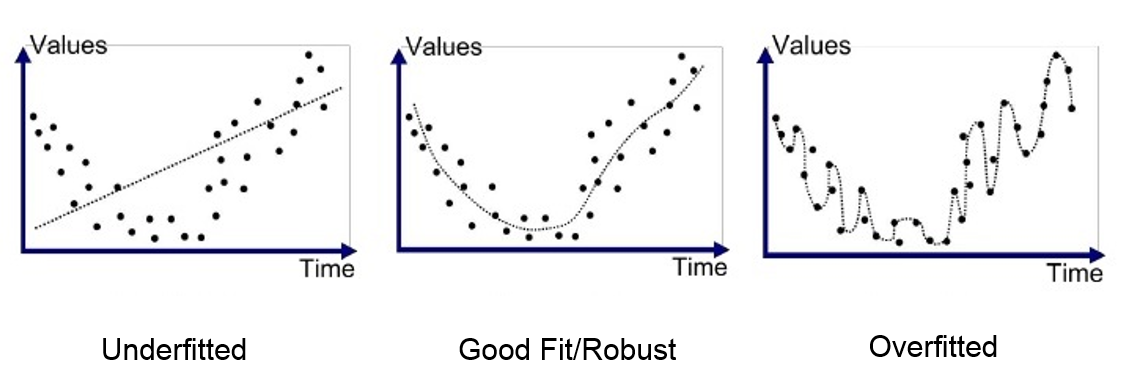
Overfitting in Regression 
Overfitting in Classification 인간은 성급한 일반화를 자주 합니다. 머신러닝에서의 모델도 이러한 현상이 발생하는데, 이것을 과적합이라고 합니다. 더 자세하게 말하자면, 학습 데이터를 너무 완벽하게 학습하여 해당 데이터는 반드시 이러한 Label을 가진다고 확신하게 되는 것입니다. 그래서 새로운 데이터를 제대로 판단하지 못하고, 오히려 잘못된 판단을 하는 것입니다. 모델을 학습시킬 때에는, 항상 손실 함수 (Loss Function)을 사용하여 평가합니다. 예를 들어 Regression에서는 MSE라는 실제와 예측의 오차 제곱의 평균값을 사용하는데, 이 값은 0에 가까워질수록 좋은 결과이지만, 또 너무 가깝거나 0이 된다면 과적합이라고 볼 수 있습니다. 오히려 성능이 실제로 테스트할 때는 아주 안 좋게 나옵니다.

Loss of overfitting 이를 해결하기 위한 방법은 다양하게 연구되고 있는데, 노이즈 제거, Feature selection과 데이터 정규화(0에서 1로 정규화하여 사용하는 방식) 같은 방식으로 과적 합의 위험을 줄일 수 있습니다. 또한 overfitting 발생 직전에 학습을 중단하는 방식을 사용합니다(Early stopping). 이를 위해서 validation set을 이용합니다.
다음 포스팅은 각각의 머신러닝 및 딥러닝관련 포스팅을 이어나가겠습니다. 머신러닝 기초와 관련된 다양한 분석 및 Scikit Learn 라이브러리를 사용한 분석은 아래의 Github 레포지토리에 있습니다. 또한 Scikit Learn 사용법을 추후 포스팅하겠습니다! 새로운 포스팅 완료!
머신러닝 (2) - ML프로젝트를 위한 데이터 선택 및 준비 (using Scikit-Learn)
Writer: Harim Kang 머신러닝 - 2. End-to-End Machine Learning Project (1) 해당 포스팅은 머신러닝의 교과서라고 불리는 Hands-On Machine Learning with Scikit-Learn & Tensor flow 책을 학습하며 정리하고,..
davinci-ai.tistory.com
https://github.com/harim4422/Scikit-Learn-Example
harim4422/Scikit-Learn-Example
Analyze and predict various data to learn how to use Scikit-learn - harim4422/Scikit-Learn-Example
github.com
Reference
-
머신러닝의 분류 이미지
-
Batch Learning VS Online Learning - https://www.researchgate.net/figure/Online-machine-learning-versus-batch-learning-a-Batch-machine-learning-workflow-b_fig1_316818527
-
그 외의 이미지 - https://www.oreilly.com/library/view/hands-on-machine-learning/9781491962282/ch01.html
https://www.tech4g.com/the-costs-of-poor-data-quality-management/
-
참고한 서적 : Hands-On Machine Learning with Scikit-learn & Tensorflow , Aurélien Géron, O'Reilly